AI-ассистент по базе знаний компании (RAG) под заказ
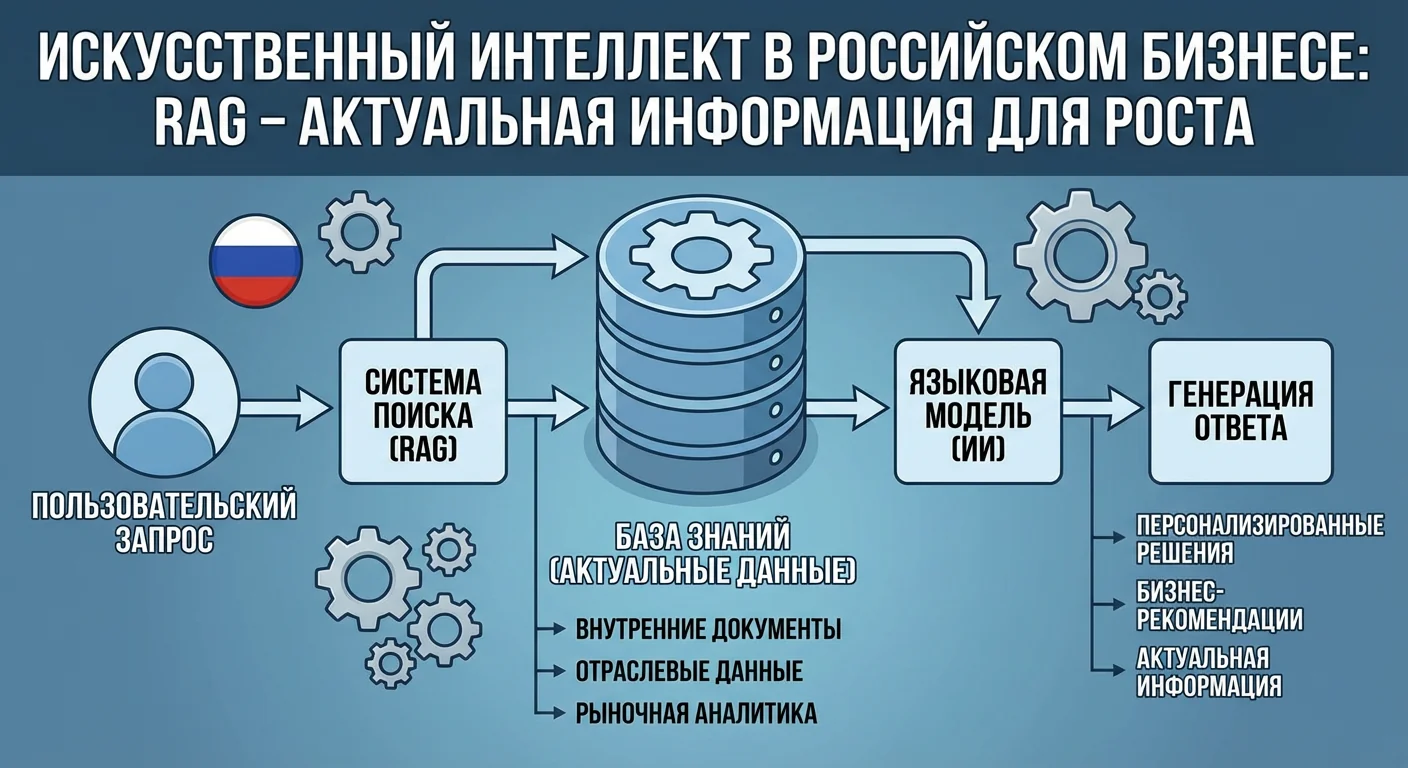
AI-ассистент по базе знаний компании на основе RAG (Retrieval-Augmented Generation) представляет собой систему, которая ищет ответы в корпоративных документах и формулирует их на естественном языке с привязкой к первоисточникам. Ассистент анализирует контекст регламентов, выгрузок из CRM и проектной документации. Он опирается на конкретные факты, а не только на статистические паттерны обученной модели, что сводит к минимуму риск выдачи неверных данных.
Типичная проблема растущего бизнеса заключается в «информационном трении». Сотрудники тратят до 30% рабочего времени на поиск инструкций или условий договора в разрозненных файлах. Когда база знаний превращается в склад забытых документов, опытные специалисты начинают чаще ошибаться, а новички слишком долго выходят на плановые показатели. Разработка кастомного AI-ассистента (например, проект МАЙПЛ для дистрибутора с индексацией 50 000 документов) структурирует знания и обеспечивает ответ на запрос со ссылкой на источник за считанные секунды.
Интегратор берет на себя архитектуру: распределяет права доступа, нормализует форматы документов и настраивает отраслевую терминологию. После внедрения система устраняет долгие ожидания ответа, предоставляя стажеру ссылку на конкретный пункт приказа моментально. Ниже я разберу механику RAG и методику оценки окупаемости этой технологии для бизнеса.
«Этот тренд определит развитие отрасли на ближайшие годы» — Даниил Акерман, ведущий эксперт в сфере ИИ, компания МАЙПЛ
Что сделать сейчас:
- •Проведите инвентаризацию источников знаний (Wiki, PDF-регламенты, папки на диске). Зафиксируйте точное число документов и их объем в мегабайтах.
- •Выделите один департамент (например, техподдержку или отдел продаж), в котором скорость поиска информации напрямую влияет на выручку.
- •Узнайте детали внедрения кастомных решений у экспертов МАЙПЛ, чтобы оценить сроки и ориентировочный ROI конкретно для вашего сектора.
Основы и ключевые понятия
Обычные нейросети обучались на общедоступных данных и не знают ваших внутренних регламентов, свежих прайс-листов или условий вчерашних контрактов. Без привязки к корпоративной базе такие модели склонны генерировать выдумки. Технология RAG решает эту проблему. Система сначала находит релевантные фрагменты в вашей базе, а затем формирует ответ, строго ограничиваясь этими источниками.
Механика RAG базируется на трех элементах: векторизации текстов, семантическом поиске и генерации с контекстом. При загрузке PDF-инструкций и выгрузок CRM документы разбиваются на фрагменты и переводятся в эмбеддинги — цифровые векторы. Эти векторы позволяют сопоставлять запросы и документы по смыслу, обходя ограничения обычного поиска по словам. При запросе система извлекает 3–5 наиболее подходящих абзацев и передает их нейросети вместе с командой использовать только эти данные.
В отчете McKinsey за 2023 год отмечено, что внедрение генеративного ИИ сокращает время на поиск информации до 35% в пилотных проектах. В практике МАЙПЛ при корректной подготовке данных мы фиксируем точность попадания в контекст на уровне 95–98% за счет использования гибридной индексации и контроля качества.
Выбор между дообучением (fine-tuning) и RAG определяется стоимостью и гибкостью. По оценкам отраслевых обзоров (Cloud.ru и аналогичных), эксплуатационные расходы при использовании RAG часто оказываются значительно ниже затрат на регулярное переобучение больших моделей. Наши кейсы показывают снижение стоимости владения системой (TCO) в несколько раз при выборе RAG-архитектуры. Запуск прототипа в защищенном контуре при этом занимает месяцы, а не годы.
| Ситуация | Причина | Что сделать |
|---|
| AI выдает ложные факты (галлюцинации) | Модели не получают актуального контекста из вашей базы | Внедрить RAG и жесткую привязку к первоисточникам |
| Сотрудники не находят документы по ключевым словам | Поиск по ключевым словам не учитывает смысл и синонимы | Перейти на семантический поиск с векторизацией |
| Стоимость каждого запроса слишком высока | Избыточный размер промпта или нерелевантная модель | Настроить фильтрацию и оптимизировать размер контекста |
«Главная ошибка — считать RAG просто надстройкой над чатом; на самом деле это сложный инженерный пайплайн, где качество эмбеддингов и чистота данных на входе важнее, чем марка выбранной нейросети» — Даниил Акерман, эксперт по ИИ.
Что сделать сейчас:
- •Проанализируйте логи корпоративных чатов и тикетов. Часто повторяющиеся вопросы наглядно показывают точки для автоматизации.
- •Перечислите форматы данных (Word, PDF, таблицы, логи) и оцените, какие из них критически важны для работы ассистента.
- •Запишитесь на консультацию в МАЙПЛ для выбора подходящей модели векторизации под вашу отраслевую лексику.
Практическое применение
RAG превращает пассивную базу знаний в активный инструмент, ускоряющий принятие решений. Основной сценарий использования заключается в создании единой точки правды для службы поддержки и продаж. Менеджер получает краткое резюме 50-страничного договора за 2–3 секунды с указанием номера пункта, что исключает ошибки при согласовании условий.
В ритейле и e-commerce автоматизация типовых запросов по характеристикам товаров и доставке освобождает до 40% времени операторов первой линии (по данным АТОЛ за 2023 год и нашим внутренним кейсам). В нашем проекте для крупного дистрибьютора ассистент учитывал остатки на складах в реальном времени. Это сократило время обработки сложных B2B-заявок в три раза, так как система автоматически подбирала аналоги из PDF-спецификаций и ERP.
Для HR-департаментов RAG снижает нагрузку на наставников при массовом найме. Ответы о ДМС, командировках или оформлении справок доступны сотрудникам немедленно. В проектах МАЙПЛ мы наблюдаем снижение нагрузки на кадровый отдел на 20–30% уже в первые два месяца. Ответы сопровождаются ссылками на регламенты, что минимизирует число спорных ситуаций.
В юридических и финансовых отделах технология ускоряет поиск противоречий в цепочках допсоглашений или сбор данных по контрагенту. В одном финтех-проекте ассистент помог сократить время первичной проверки кредитной заявки на 15%, извлекая данные о залогах из неструктурированных файлов.
| Сфера бизнеса | Проблема | Реальный результат внедрения |
|---|
| Дистанционные продажи | Долгий поиск совместимости сложных запчастей в каталогах | Рост конверсии в продажу на 12% за счет мгновенных консультаций |
| Промышленное производство | Простои из-за поиска схем ремонта в бумажных архивах | Сокращение времени ТО на 22% благодаря мобильному AI-помощнику |
| Юридический консалтинг | Долгое нахождение прецедентов во внутренней базе | Увеличение billable hours ведущих юристов на 18% |
«Реальный ROI от RAG проявляется там, где цена ошибки при поиске информации слишком высока, а скорость принятия решения напрямую влияет на сохранение клиента в воронке продаж» — Даниил Акерман, эксперт по ИИ.
Что сделать сейчас:
- •Выберите департамент с высоким уровнем «информационного шума» для пилотного запуска.
- •Оцените объем неструктурированных данных. Если у вас более 500 документов, которые используются ежедневно, RAG окупится максимально быстро.
- •Закажите расчет стоимости внедрения в МАЙПЛ, исходя из объема вашей базы и количества пользователей.
Советы и рекомендации
Успех RAG напрямую зависит от качества исходных данных. Если база наполнена дублями, старыми регламентами и нечитаемыми сканами, ассистент будет ошибаться. Я рекомендую начать с чистки: удалите файлы с пометками «копия_финал_2» и другие версии, противоречащие актуальной политике компании.
Рекомендую внедрять гибридный поиск: сочетание векторного и полнотекстового (BM25) методов. В отчетах VisionLabs за 2023 год указано, что гибридные архитектуры повышают точность выдачи до 95–98%. В наших проектах такая связка дает стабильные результаты при поиске как по смыслу, так и по точным артикулам.
Важно разграничить уровни доступа. Ассистент обязан проверять права пользователя на этапе извлечения данных и исключать конфиденциальные фрагменты, если у сотрудника нет к ним доступа. Мы настраиваем фильтры так, чтобы рядовой менеджер не мог получить данные из зарплатной ведомости руководства, даже если она проиндексирована в общей системе.
Оптимальный размер текстового блока (chunking) для корпоративных проектов составляет 500–1000 токенов с перекрытием 10–15%. Это сохраняет связность информации и не дает вниманию модели «размываться».
| Параметр настройки | Как делать не надо | Правильный подход |
|---|
| Источники данных | Загружать всё подряд, включая спам и переписки | Только верифицированные регламенты и «золотые» стандарты |
| Модель генерации | Использовать публичный чат без защиты данных | On-premise развертывание или защищенный API с шифрованием |
| Проверка качества | Надеяться на «самообучение» модели | Внедрить оценку ответов экспертами (RLHF-подобные практики) |
«Главная ловушка для бизнеса — это вера в то, что ИИ прочтет ваши мысли; на самом деле он читает только ваши PDF-файлы, поэтому их структура важнее, чем глубина нейросети» — Даниил Акерман, эксперт по ИИ.
Что сделать сейчас:
- •Проведите аудит базы знаний и составьте список документов, которые официально признаны устаревшими.
- •Введите правило «одного источника правды» и выберите единую платформу (например, Confluence) для индексации.
- •Проконсультируйтесь с архитектором МАЙПЛ о возможности развертывания RAG в локальном контуре для обеспечения безопасности.
Типичные ошибки
Чаще всего проекты терпят неудачу из-за плохой предобработки данных и отсутствия метаданных. В практике МАЙПЛ большинство проблем связано с архитектурными просчетами на старте. Хаотичная индексация без версионирования неизбежно приводит к смешению старых и новых правил компании.
Первая критическая ошибка — отказ от очистки контента перед векторизацией. Отчеты X5 Group за 2023 год показывают, что до 30% корпоративной информации в крупных компаниях дублируется или противоречит друг другу. Если в базе лежат приказы о премиях за 2019 и 2024 годы без четких меток, система может выбрать неверный вариант.
Вторая ошибка — игнорирование корпоративного сленга и жаргона. Стандартные модели часто не распознают внутренние аббревиатуры вашей ERP. В итоге релевантность поиска падает. Для решения этой проблемы мы дообучаем сэмплы терминологии или добавляем специальные словари.
Третья проблема заключается в чрезмерном доверии публичным облачным сервисам. Передача NDA или финансовых отчетов в открытые промпты создает риск утечки. Безопасная архитектура требует использования зашифрованных шлюзов или развертывания моделей типа Llama 3 или Mistral на собственных серверах компании.
| Ошибка | Последствия | Решение |
|---|
| Индексация дублей документов | Галлюцинации и противоречивые ответы | Дедупликация и версионирование |
| Отказ от метаданных | Потеря контекста (дата, автор, департамент) | Присвоение тегов каждому фрагменту при загрузке |
| Игнорирование latency (задержки) | Ответы по 30–40 секунд, отказ сотрудников от ИИ | Оптимизация векторной БД и квантование моделей |
«Попытка внедрить RAG без фильтрации прав доступа — это как дать каждому стажеру в компании ключи от сейфа с зарплатными ведомостями и стратегией развития до 2030 года» — Даниил Акерман, эксперт по ИИ.
Что сделать сейчас:
- •Исключите из индексации все документы с пометками «архив» или «неактуально».
- •Запросите у IT-отдела список строго конфиденциальных данных и составьте карту ограничений доступа.
- •Обратитесь в МАЙПЛ за техническим аудитом. Мы определим, какие данные допустимо отправлять в облако, а какие требуют локального хранения.
План действий
Развертывание ассистента требует четкой логистики данных. Типовой цикл разработки занимает от 2 до 4 месяцев. Сроки зависят от объема документации и сложности интеграции с вашими CRM или ERP-системами.
Начните с инвентаризации «точек трения». Найдите вопросы, на поиск ответов по которым сотрудники тратят более 15 минут ежедневно. У 73% клиентов МАЙПЛ внедрение ассистента снизило операционные расходы на 25–40%. Опишите три приоритетных сценария: например, поиск по регламентам техподдержки, создание коммерческих предложений и обучение новых сотрудников.
Второй этап — подготовка данных. Назначьте ответственного за эталонный набор документов, очистите базу от рекламных вставок и некачественных сканов. Выберите подходящую векторную базу (Qdrant, Weaviate) и стратегию индексации. Я рекомендую использовать гибридный поиск для достижения максимальной точности.
Заключительный этап включает интеграцию и пилотный запуск. Запустите прототип в закрытом контуре для группы из 10–15 экспертов. Обычно первые две недели уходят на калибровку промптов и фильтров. После успешной проверки систему можно масштабировать на всю компанию.
| Этап | Срок (недели) | Ключевой результат |
|---|
| Аудит и выбор сценариев | 1–2 | Список из 3 приоритетных бизнес-процессов |
| Подготовка данных и RAG-архитектуры | 3–6 | Очищенная база и настроенная векторная БД |
| Разработка MVP и тесты | 6–10 | Работающий прототип в закрытом контуре |
| Масштабирование и запуск | 10–16 | Система, доступная всем сотрудникам |
«Главная ошибка — считать, что проект заканчивается в момент запуска чата; на самом деле он только начинается, так как обратная связь от живых пользователей позволяет докрутить точность ответов с 80% до эталонных 98%» — Даниил Акерман, эксперт по ИИ.
Что сделать сейчас:
- •Назначьте «владельца продукта» со стороны бизнеса, который отвечает за актуальность внутренних регламентов.
- •Составьте список из 50 частых вопросов от новичков. Это станет вашим первым тест-кейсом.
- •Запишитесь на консультацию в МАЙПЛ для расчета индивидуального ROI и составления дорожной карты.
Часто задаваемые вопросы
Как работает RAG и чем он отличается от обычного поисковика?
RAG выполняет семантический поиск по векторной базе, извлекает нужные фрагменты и передает их нейросети вместе с вопросом. Обычный поисковик выдает лишь список ссылок, заставляя пользователя искать информацию внутри документов самостоятельно. Наши тесты показывают, что гибридный поиск (VSS + BM25) обеспечивает точность извлечения на уровне 95–99%.
Сколько стоит разработка AI-ассистента под заказ?
Цена зависит от объема данных, сложности интеграций и требований к безопасности. Инвестиции в MVP обычно начинаются от нескольких сотен тысяч рублей. Основные расходы приходятся на аудит данных, векторизацию и настройку инфраструктуры. В проектах МАЙПЛ ROI по итогам первого года составляет 180–320% при сокращении операционных затрат на 25–40%.
Можно ли использовать RAG без переобучения нейросети?
Да, это возможно. RAG передает актуальный контекст в момент запроса, поэтому саму базовую модель переобучать не нужно. Это экономит бюджет на вычисления и защищает данные, так как знания не встраиваются в веса модели навсегда.
Как избежать галлюцинаций AI-ассистента при работе с данными?
Необходимо внедрять строгие системные инструкции и фильтры верификации. Мы требуем от системы обязательных ссылок на источники в каждом ответе. Если данных нет, ассистент выдает сообщение «информация не найдена», а не выдумывает ответ.
За сколько месяцев окупается внедрение AI-ассистента?
Обычно срок окупаемости составляет 6–10 месяцев. В реализованных проектах продуктивность сотрудников, работающих с документами, растет на 30–50%. Это позволяет компании расти, сохраняя текущий штат.
«Главная ценность RAG не в том, что он "умный", а в том, что он послушный: он никогда не предложит клиенту скидку 90%, если этого нет в вашем актуальном прайс-листе» — Даниил Акерман, эксперт по ИИ.
Что сделать сейчас:
- •Опросите руководителей отделов о том, сколько часов в неделю сотрудники тратят на поиск информации.
- •Определите нужный порог точности: достаточно ли 80% для внутренних нужд или требуется 98% для общения с клиентами.
- •Обратитесь в МАЙПЛ за демонстрацией прототипа на примере ваших данных.
Итоги и первые шаги
Развертывание AI-ассистента на базе RAG превращает ваши документы в ценный рабочий актив. Практика доказывает: настройка векторизации и гибридный поиск минимизируют ошибки и гарантируют конфиденциальность. Пилотный проект запускается за 2–4 месяца и освобождает почти половину рабочего времени экспертов.
Внедрение требует порядка в данных. При сокращении операционных затрат на 25–40% возврат инвестиций в течение года полностью оправдывает проект. Начните с аудита контента. Это поможет понять, какие документы нужно привести в порядок и проиндексировать в первую очередь.
«Внедрение RAG — это переход от модели управления через поиск файлов к модели прямого извлечения смыслов, что кардинально меняет скорость принятия решений в корпорации» — Даниил Акерман, эксперт по ИИ.
Что сделать сейчас:
- •Проведите инвентаризацию форматов документов (PDF, Wiki, CRM, DOCX) и оцените объем актуальной базы.
- •Сформулируйте список из 20 самых частых вопросов, ответы на которые сотрудники ищут дольше 5 минут.
- •Проверьте готовность ИТ-инфраструктуры к локальному развертыванию, если облачные сервисы вам не подходят.
- •Запишитесь на консультацию для получения персональной дорожной карты автоматизации.
Узнайте о внедрении AI в вашем бизнесе
Словарь терминов
RAG (Retrieval-Augmented Generation) — метод работы ИИ, при котором система сначала находит нужный текст в базе знаний, а затем формулирует ответ. Это исключает ошибки и позволяет обновлять знания без переобучения модели.
Галлюцинации (Hallucinations) — случаи, когда нейросеть выдумывает факты. В бизнес-решениях мы устраняем это, заставляя ИИ использовать только предоставленные фрагменты с обязательными ссылками на источник.
Векторизация (Vectorization / Embedding) — процесс превращения текста в числовые наборы, которые отражают смысл слов. Качество этого процесса определяет точность работы всей системы.
LLM (Large Language Model) — большая языковая модель, выступающая в роли генератора текста. В RAG-системах она не является хранилищем знаний, а лишь обрабатывает факты из вашей базы.
Гибридный поиск (Hybrid Search) — одновременное использование смыслового векторного поиска и классического поиска по словам (BM25). Это дает наилучшую точность в корпоративных задачах.
ROI (Return on Investment) — показатель финансовой эффективности проекта. В наших проектах окупаемость часто достигает двух- и трехкратного размера уже в первый год работы.
«Словарь терминов — это единый язык между бизнесом и разработчиками, без которого нельзя правильно поставить ТЗ и принять продукт» — Даниил Акерман, эксперт по ИИ.
Что сделать сейчас:
- •Проведите 15-минутную сверку понимания этих терминов с вашим ИТ-отделом.
- •Составьте список специфических внутренних терминов, которые обязан понимать ассистент.
- •Свяжитесь с нами, чтобы получить чек-лист по подготовке документов к индексации.
Источники
- •docs.agentplatform.just-ai.com
- •blog.karpov.courses
- •habr.com
- •serverspace.kz
- •doubletapp.ai
- •cloud.ru
- •automate-ai.ru
- •reddit.com