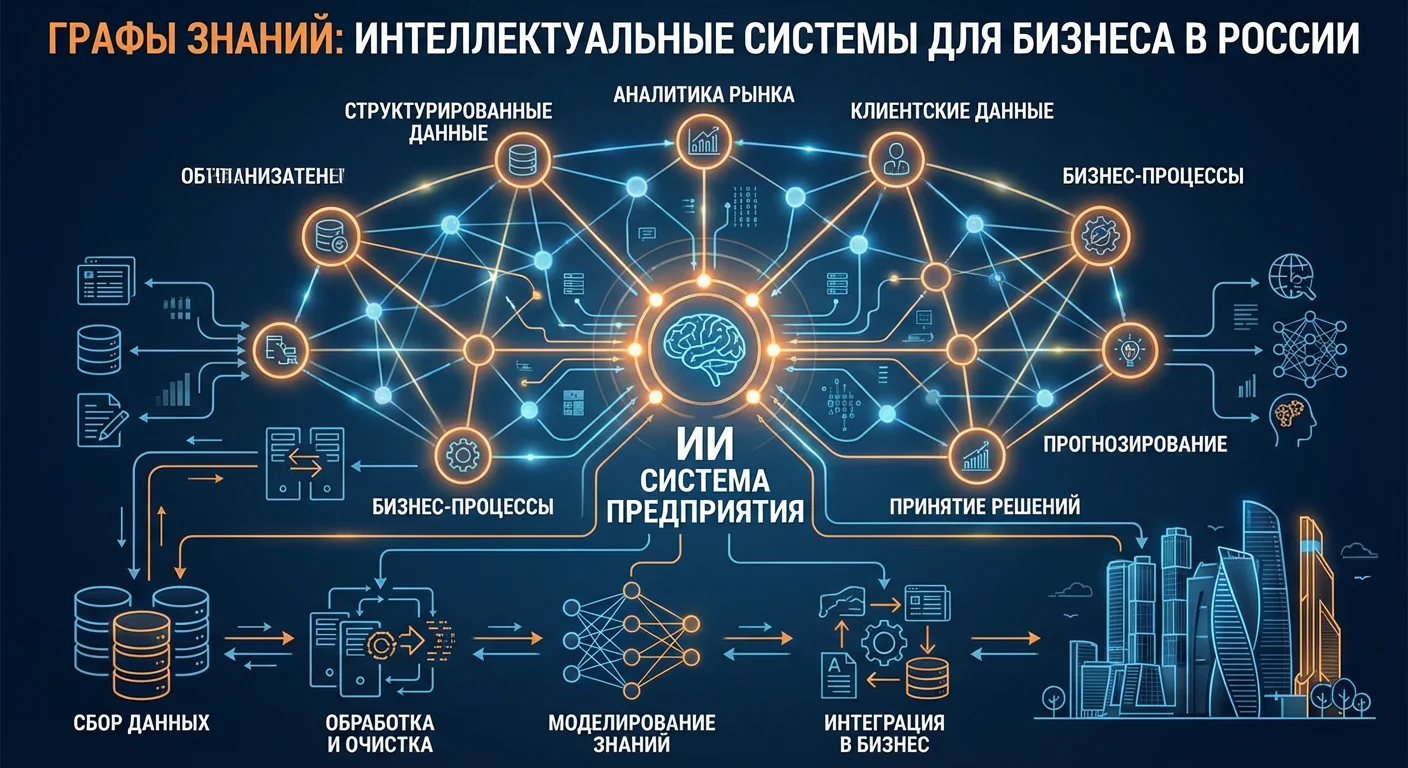
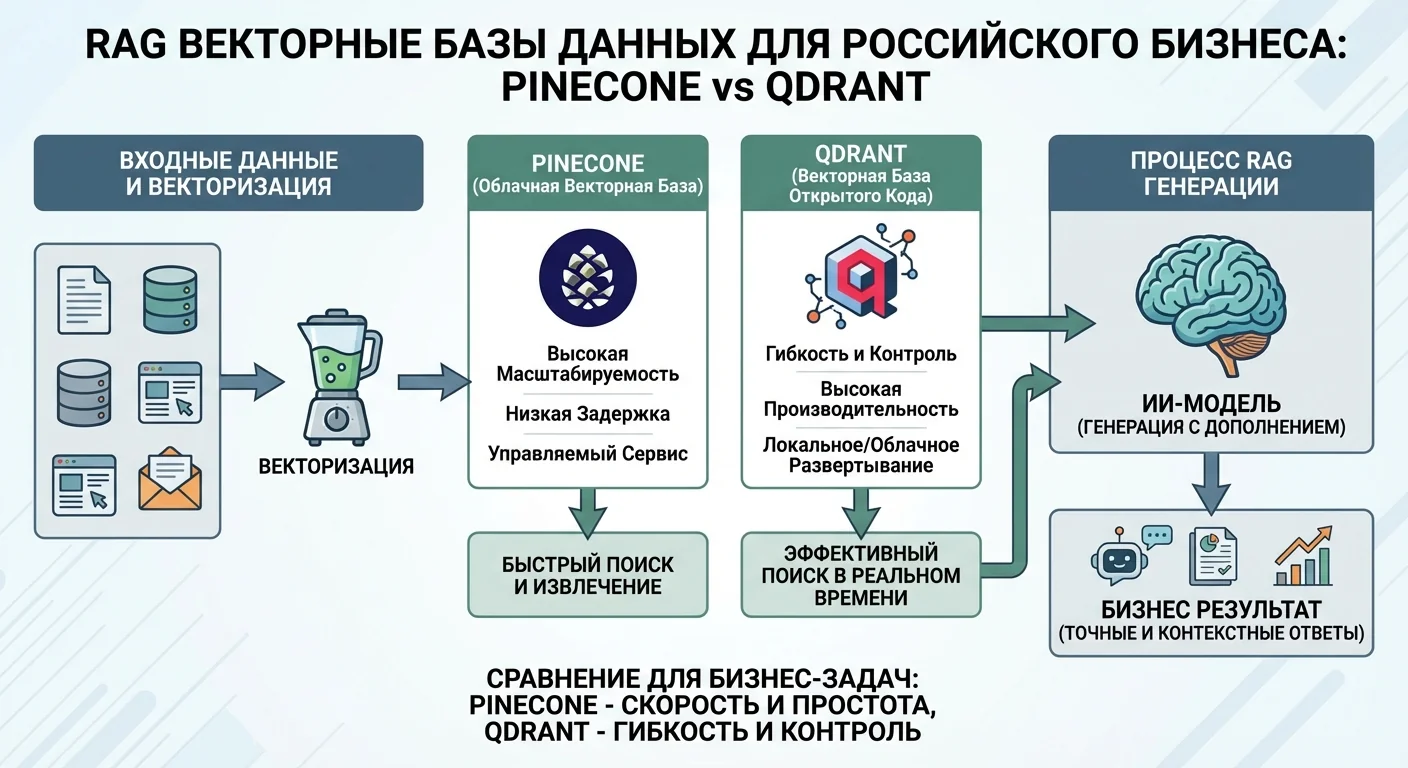
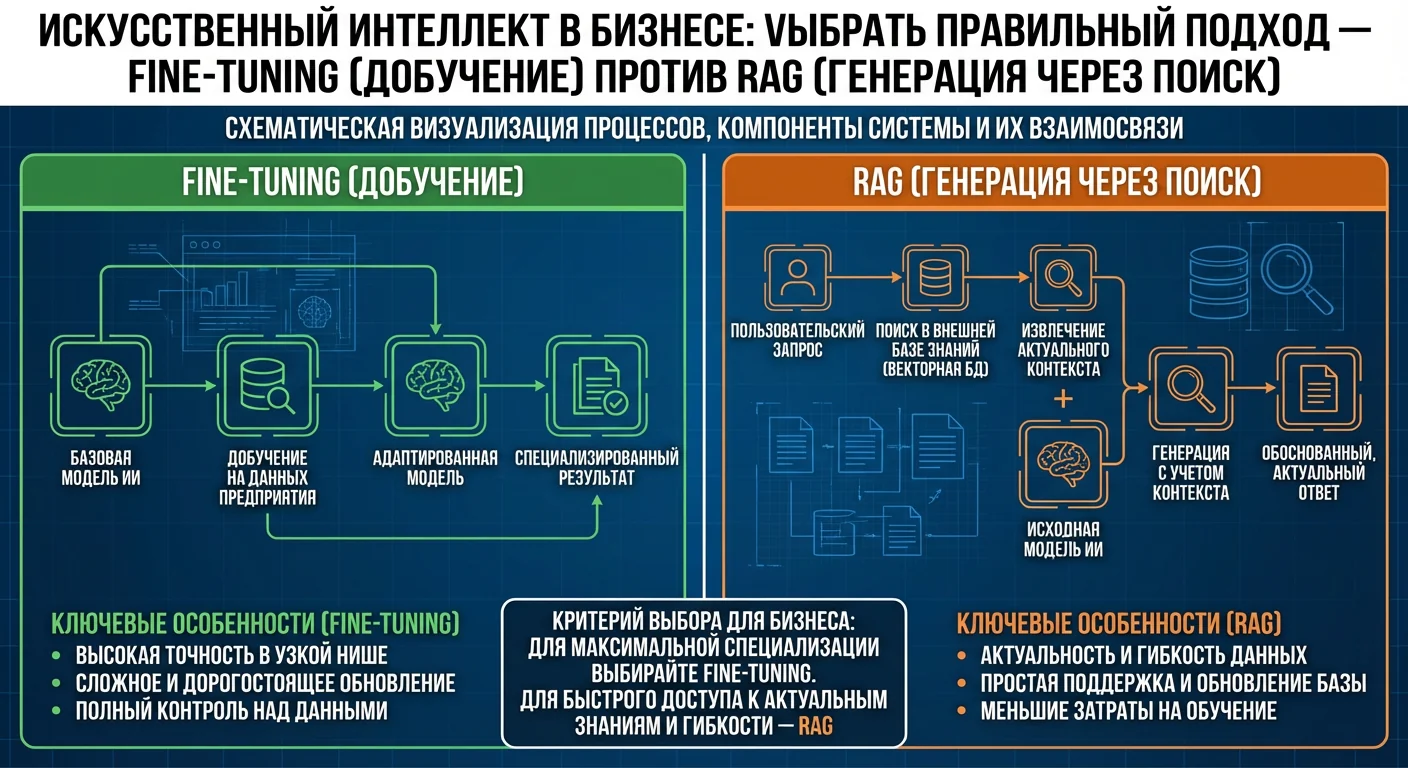
Если вы хотите внедрить RAG (AI с вашей базой знаний), вам нужна Vector Database. Это база данных, которая хранит "выученные" представления ваших документов и быстро находит нужные куски когда вы задаете вопрос. В этой статье я объясню, что это, почему нужна, и сравню Pinecone, Weaviate, Qdrant.
Что такое Vector Database
Проблема: вы загружаете 10000 документов в ChatGPT. Каждый документ содержит информацию. Как ChatGPT быстро найти нужный документ, когда вы задаете вопрос?
Решение: Vector Database.
Vector Database преобразует документы в "векторы" (числовые представления). Когда вы задаете вопрос, он тоже преобразуется в вектор. Система находит самые похожие документы (используя расстояние между векторами).
Простой пример: если у вас есть документы на тему "возврат товара" и "доставка товара", и вы спрашиваете "как вернуть товар", система найдет документ о возврате (потому что вектор вопроса ближе к вектору документа о возврате).
Зачем нужна Vector Database для AI
Без Vector Database (обычный ChatGPT): вы загружаете документ, ChatGPT читает весь документ и отвечает на вопрос. Это работает для небольших объемов данных.
Проблема: если документов 10000, ChatGPT не может обработать все сразу (есть лимит на размер контекста). Это ограничение делает невозможным работу с большими базами знаний без специальных решений.
С Vector Database (RAG система):
- •Вы загружаете документы в Vector Database.
- •Система преобразует документы в векторы.
- •Когда вы спрашиваете, система находит 3–5 самых похожих документов.
- •Эти документы отправляются в ChatGPT.
- •ChatGPT отвечает на основе найденных документов.
Результат: система может работать с 1 млн документов, но каждый раз обрабатывает только 5–10 релевантных.
Сравнение: Pinecone vs Weaviate vs Qdrant
| Параметр | Pinecone | Weaviate | Qdrant |
|---|
| Тип | Облачная | Облачная + локальная | Облачная + локальная |
| Стоимость | $87–5000+/месяц | $100–бесплатно* | $0–бесплатно (локально) |
| Скорость | Очень быстрая | Быстрая | Очень быстрая |
| Простота | Очень простая | Средняя | Средняя |
| Масштабируемость | Отличная | Хорошая | Отличная |
| Интеграции | Много (LangChain, Zapier) | Много | Растет |
| Документация | Отличная | Отличная | Хорошая |
| Для кого | Стартапы, быстро | Enterprise, гибкость | Enterprise, контроль |
*Weaviate имеет free облачный вариант с ограничениями.
Pinecone: самый простой выбор для начинающих
Плюсы:
- •Очень простой API, легко начать.
- •Хорошая документация и примеры.
- •Хорошо интегрируется с LangChain, Zapier.
- •Автоматическое масштабирование.
Минусы:
- •Дорого при больших объемах.
- •Нет локального варианта.
- •Зависит от облака Pinecone.
Стоимость:
- •Starter: $87/месяц (2 индекса, 625 размер вектора).
- •Pro: $500+/месяц (зависит от использования).
Когда выбрать: для стартапов, для быстрого прототипирования, если не хотите заморачиваться с инфраструктурой.
Пример: RAG система для e-commerce, 1000 товаров, 100 запросов в день.
- •Стоимость: $87/месяц.
- •Результат: работает из коробки, быстро.
Weaviate: гибкость и возможности
Плюсы:
- •Есть облачный и локальный вариант.
- •Модульная архитектура, много возможностей.
- •Хорошая масштабируемость.
- •GraphQL API.
Минусы:
- •Более сложный в настройке.
- •Требует больше знаний DevOps.
- •Облачная версия дороговата.
Стоимость:
- •Локально: бесплатно (но нужен сервер).
- •Облако: $100–$2000+/месяц.
Когда выбрать: для enterprise компаний, которым нужна гибкость и контроль.
Пример: RAG система для внутреннего использования в крупной компании, миллион документов.
- •Стоимость: сервер $500/месяц + управление.
- •Результат: полный контроль, можно настроить под нужды.
Qdrant: производительность и контроль
Плюсы:
- •Отличная производительность.
- •Есть облачный и локальный вариант.
- •Быстро развивается.
- •Хорошее сообщество.
Минусы:
- •Менее известный (меньше примеров).
- •Меньше интеграций чем Pinecone/Weaviate.
- •Документация менее подробная.
Стоимость:
- •Локально: бесплатно.
- •Облако: $0–$500+/месяц (зависит).
Когда выбрать: если нужна максимальная производительность и контроль.
Как выбрать: практический подход
Вопрос 1: Сколько документов?
- •< 100K → Pinecone Starter.
- •100K–1M → Qdrant локально или Weaviate облако.
- •
1M → Weaviate или Qdrant локально.
Вопрос 2: Критична ли приватность?
- •Да → Qdrant или Weaviate локально.
- •Нет → Pinecone.
Вопрос 3: Бюджет?
- •< $100/месяц → Weaviate free или Qdrant локально.
- •$100–500 → Pinecone Pro или Weaviate облако.
- •
$500 → любой, выбирайте по функциям.
Вопрос 4: Нужны ли интеграции?
- •Да → Pinecone (лучше всех).
- •Нет → любой.
Пошаговый план внедрения
Этап 1: выберите Vector Database на основе ответов выше.
Этап 2: создайте free trial аккаунт, протестируйте.
Этап 3: загрузите 100 тестовых документов, создайте простой RAG.
Этап 4: задайте 10 вопросов, проверьте, что система находит правильные документы.
Этап 5: если всё работает, масштабируйте.
Интеграция с LangChain (самый популярный способ)
from langchain.vectorstores import Pinecone
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
# Создаем RAG цепочку
vector_store = Pinecone.from_existing_index(
index_name="my-index",
embedding=OpenAIEmbeddings()
)
qa = RetrievalQA.from_chain_type(
llm=ChatOpenAI(),
chain_type="stuff",
retriever=vector_store.as_retriever()
)
# Задаем вопрос
result = qa.run("Как вернуть товар?")
Это всё, система автоматически найдет документы и ответит.
Метрики: как контролировать качество
| Метрика | Целевое значение |
|---|
| Precision (насколько релевантны найденные документы) | > 90% |
| Recall (насколько мы нашли все релевантные) | > 80% |
| Время поиска | < 100ms |
| Стоимость за запрос | < $0.001 |
Заключение: Vector Database — основа для AI в 2026
Vector Database — это не опция, это необходимость если вы хотите RAG. Выберите на основе вашего бюджета и требований, начните с пилота, масштабируйте.
Детальное сравнение по конкретным задачам
Чтобы лучше понять, какая Vector Database подходит для ваших задач, сравним их по конкретным сценариям:
Сценарий 1: Стартап с небольшой базой знаний
У вас 1000-10000 документов, нужна быстрая настройка, бюджет ограничен.
Рекомендация: Pinecone Starter ($87/месяц). Простая настройка, хорошая документация, достаточно для небольшой базы. Если бюджет очень ограничен — Weaviate free или Qdrant локально.
Сценарий 2: Средняя компания с большой базой знаний
У вас 100000-1000000 документов, нужна производительность, бюджет средний.
Рекомендация: Qdrant локально или Weaviate облако. Хорошая производительность, масштабируемость, контроль над данными. Стоимость: $200-1000 в месяц.
Сценарий 3: Крупная компания с требованиями приватности
У вас миллионы документов, критична приватность, нужен полный контроль.
Рекомендация: Qdrant или Weaviate локально. Полный контроль над данными, приватность гарантирована, можно настроить под нужды. Стоимость: сервер $500-2000 в месяц + управление.
Сценарий 4: Компания с частыми обновлениями
Документы часто обновляются, нужна быстрая синхронизация.
Рекомендация: Pinecone или Qdrant. Хорошая поддержка обновлений, быстрая синхронизация. Weaviate тоже поддерживает обновления, но может быть медленнее.
Типичные проблемы с Vector Database и как их решить
При использовании Vector Database часто возникают проблемы. Вот самые частые:
Проблема 1: Медленный поиск
Поиск занимает много времени, пользователи жалуются на медленную работу. Причина: большая база документов, медленная векторная база, неоптимальные запросы.
Решение: используйте быструю векторную базу (Pinecone, Qdrant), оптимизируйте размер векторов, ограничьте количество результатов поиска, используйте индексы.
Проблема 2: Низкая точность поиска
Система находит не те документы, ответы нерелевантные. Причина: плохие embeddings, неправильный размер кусков, неправильная метрика расстояния.
Решение: используйте качественные модели для embeddings (OpenAI, Cohere), оптимизируйте размер кусков, экспериментируйте с метриками расстояния, используйте метаданные для фильтрации.
Проблема 3: Высокая стоимость
Затраты на векторную базу превышают бюджет. Причина: большая база документов, много запросов, дорогая облачная база.
Решение: используйте локальные решения (Qdrant, Weaviate), оптимизируйте размер базы документов, ограничьте количество запросов, используйте кэширование.
Проблема 4: Проблемы с масштабированием
Система не справляется с ростом базы документов или количества запросов. Причина: ограничения векторной базы, недостаточные ресурсы.
Решение: используйте масштабируемые решения (Pinecone, Qdrant), увеличите ресурсы, оптимизируйте запросы, используйте горизонтальное масштабирование.
Проблема 5: Сложность настройки
Сложно настроить векторную базу, требуется много времени и знаний. Причина: сложная документация, недостаточно примеров, требует знаний DevOps.
Решение: используйте простые решения (Pinecone), используйте готовые примеры, обратитесь за помощью к разработчику или консультанту.
Пошаговый план выбора и внедрения Vector Database
Если вы решили использовать Vector Database, следуйте этому плану:
Неделя 1: Оценка требований
Определите ваши требования: сколько документов, сколько запросов в день, критична ли приватность, какой бюджет. Это поможет выбрать подходящую векторную базу.
Неделя 2: Выбор платформы
На основе требований выберите платформу: Pinecone для простоты, Weaviate для гибкости, Qdrant для производительности. Создайте пробный аккаунт, протестируйте базовую функциональность.
Неделя 3: Разработка и интеграция
Разработайте интеграцию Vector Database с вашей системой. Это может сделать разработчик за 20-40 часов. Интегрируйте с AI моделью (ChatGPT API, Claude API), настройте поиск и генерацию ответов.
Неделя 4: Тестирование
Протестируйте систему на реальных данных. Загрузите 100-500 тестовых документов, задайте 10-20 вопросов, проверьте качество ответов. Оптимизируйте настройки: размер кусков, количество результатов поиска, метрики расстояния.
Месяц 2: Масштабирование
Если тестирование успешно, масштабируйте систему: загрузите все документы, запустите для всех пользователей. Продолжайте отслеживать метрики, собирать обратную связь, оптимизировать.
Месяц 3: Оптимизация
Проанализируйте результаты: какие настройки работают лучше всего, где возникают проблемы, как можно улучшить. Оптимизируйте систему: улучшите embeddings, оптимизируйте размер кусков, улучшите поиск.
Часто задаваемые вопросы
Вопрос 1: Можно ли использовать Vector Database без RAG?
Технически можно, но это не имеет смысла. Vector Database нужна именно для RAG систем, где нужно быстро находить релевантные документы из большой базы. Для других задач Vector Database не нужна.
Вопрос 2: Сколько документов можно загрузить в Vector Database?
Зависит от платформы. Pinecone позволяет загружать миллионы документов, Qdrant и Weaviate тоже поддерживают большие объемы. Но для начала достаточно 1000-10000 документов. По мере роста можно добавлять больше.
Вопрос 3: Как часто нужно обновлять документы в Vector Database?
Зависит от типа документов. Если документы часто меняются (политики, инструкции), обновляйте их сразу после изменений. Если документы стабильные (исторические данные), обновляйте раз в месяц или реже.
Вопрос 4: Можно ли использовать Vector Database для конфиденциальных данных?
Да, можно. Используйте локальные решения (Qdrant, Weaviate локально), храните векторы на своем сервере. Это дороже облачных решений, но гарантирует приватность данных. Для критичных данных это необходимо.
Вопрос 5: Как понять, что Vector Database работает эффективно?
Есть несколько признаков: система быстро находит релевантные документы, ответы точные и релевантные, пользователи довольны, затраты в пределах бюджета. Отслеживайте метрики: точность поиска, скорость работы, стоимость, удовлетворенность пользователей.
Словарь терминов
- •Vector Database — база данных, хранящая векторные представления документов.
- •Вектор — числовое представление текста.
- •Embedding — процесс преобразования текста в вектор.
- •RAG (Retrieval-Augmented Generation) — система, использующая Vector Database для AI.
- •API (Application Programming Interface) — интерфейс для интеграции.
- •LangChain — библиотека для создания RAG систем.
- •GraphQL — язык запросов для API.
- •Масштабируемость — способность системы работать с большими объемами.
- •Precision — точность поиска.
- •Recall — полнота поиска.