Vector Databases для RAG: Pinecone vs Qdrant vs FAISS vs Milvus
Vector Databases для RAG: Pinecone vs Qdrant vs FAISS vs Milvus
АВТОР
Даниил Акерман
ДАТА ПУБЛИКАЦИИ
23 декабря 2025 г.
КАТЕГОРИЯ
ML
ВРЕМЯ ЧТЕНИЯ
14 минут
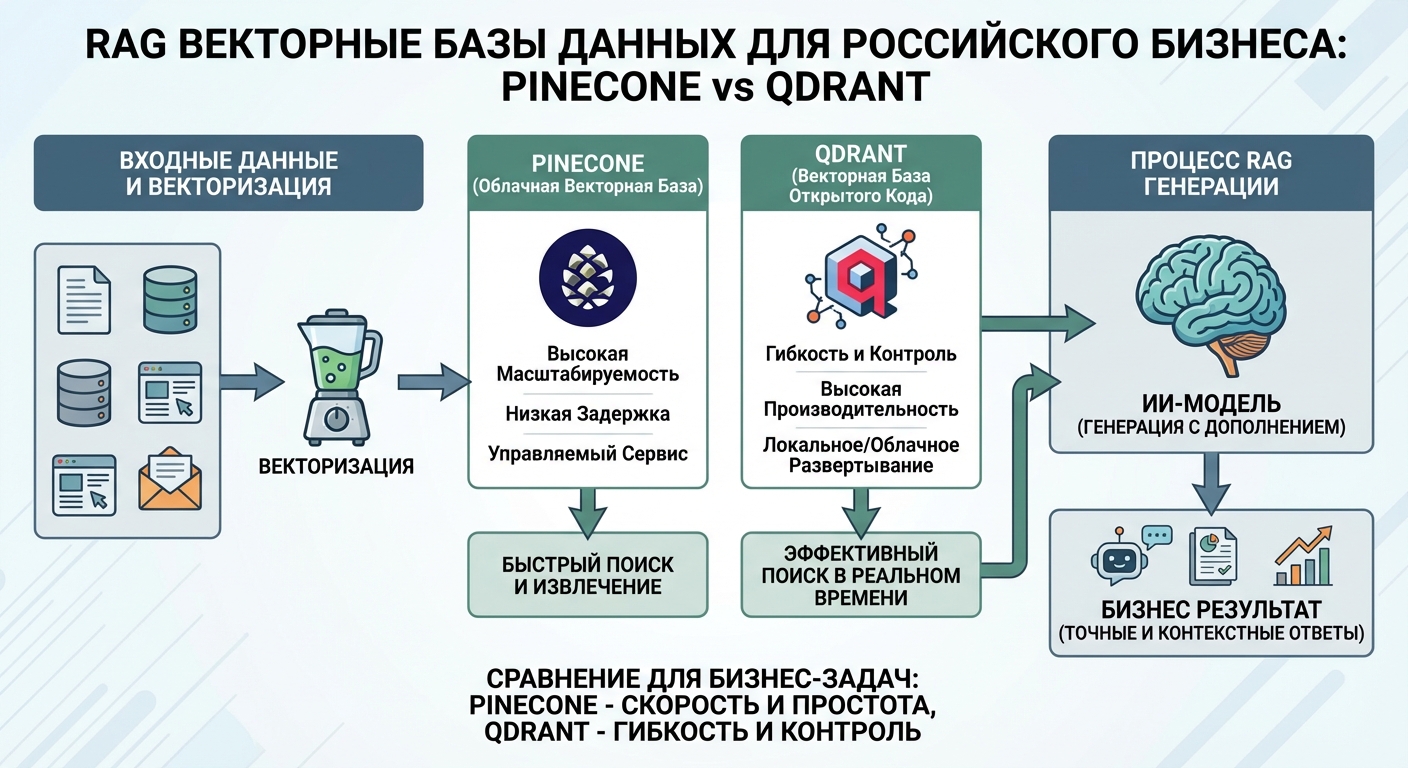
RAG (Retrieval-Augmented Generation) системы стали стандартом для создания AI-приложений, которые работают с актуальной информацией. Ключевой компонент RAG-системы — векторная база данных, которая хранит embeddings документов и позволяет быстро находить релевантную информацию. Выбор правильной векторной базы данных критически важен для производительности, масштабируемости и стоимости RAG-системы.
Векторные базы данных специально оптимизированы для хранения и поиска векторов — числовых представлений текста, изображений или других данных. В отличие от традиционных баз данных, векторные БД используют специальные алгоритмы индексации для быстрого поиска похожих векторов, что делает их идеальными для RAG-систем. Понимание различий между различными векторными базами данных помогает выбрать оптимальное решение для конкретной задачи.
В 2025 году рынок векторных баз данных представлен множеством решений: от облачных сервисов типа Pinecone до open-source решений типа Qdrant, FAISS и Milvus. Каждое решение имеет свои преимущества и недостатки в зависимости от требований к масштабу, производительности, стоимости и простоте использования. Как выбрать правильную векторную базу данных? Какие факторы учитывать? В этой статье мы разберем особенности основных векторных баз данных, сравним их по ключевым параметрам и дадим рекомендации по выбору.
Что такое векторные базы данных и зачем они нужны
Векторные базы данных — это специализированные системы хранения данных, оптимизированные для работы с векторами — многомерными массивами чисел, которые представляют семантическое значение данных. Понимание принципов работы векторных баз данных помогает эффективно использовать их в RAG-системах.
Векторы как представление смысла — тексты, изображения и другие данные преобразуются в векторы с помощью моделей embeddings. Векторы, которые семантически близки, находятся близко друг к другу в векторном пространстве. Это позволяет находить похожие документы по их семантическому сходству, а не только по точному совпадению текста. Векторное представление данных открывает новые возможности для поиска и анализа информации.
Поиск по сходству — векторные базы данных используют специальные алгоритмы индексации для быстрого поиска векторов, похожих на запрос. Алгоритмы типа HNSW (Hierarchical Navigable Small World) или IVF (Inverted File Index) позволяют находить похожие векторы за миллисекунды даже в миллионах векторов. Скорость поиска критически важна для RAG-систем, где задержка влияет на пользовательский опыт. Эффективный поиск по сходству — ключевое преимущество векторных баз данных.
Масштабируемость — векторные базы данных разработаны для работы с большими объемами данных. Они могут хранить миллионы и даже миллиарды векторов, обеспечивая быстрый поиск независимо от объема данных. Масштабируемость важна для RAG-систем, которые работают с большими корпоративными базами знаний или постоянно растущими наборами документов. Способность масштабироваться определяет применимость решения для различных задач.
Интеграция с RAG — векторные базы данных являются ключевым компонентом RAG-систем. Они хранят embeddings документов, которые используются для поиска релевантной информации при генерации ответов. Качество поиска в векторной базе данных напрямую влияет на качество ответов RAG-системы. Понимание роли векторных баз данных в RAG помогает оптимизировать работу системы.
Pinecone: облачное решение для быстрого старта
Pinecone — это полностью управляемая облачная векторная база данных, которая упрощает работу с векторами для разработчиков. Платформа предоставляет простой API и автоматически управляет инфраструктурой, что делает ее привлекательной для быстрого старта проектов.
Простота использования — Pinecone предоставляет простой REST API и SDK для различных языков программирования. Регистрация и начало работы занимают минуты, не требуется настройка инфраструктуры или управление серверами. Простота использования делает Pinecone привлекательным для команд, которые хотят быстро запустить RAG-систему без глубоких знаний инфраструктуры. Минимальная настройка позволяет фокусироваться на разработке функциональности, а не на управлении инфраструктурой.
Автоматическое масштабирование — Pinecone автоматически масштабируется в зависимости от нагрузки и объема данных. Не нужно беспокоиться о планировании ресурсов или управлении кластерами. Автоматическое масштабирование упрощает работу и обеспечивает производительность независимо от нагрузки. Это особенно полезно для проектов с переменной нагрузкой или растущим объемом данных.
Производительность — Pinecone оптимизирован для высокой производительности поиска. Платформа использует современные алгоритмы индексации и оптимизированную инфраструктуру для обеспечения низкой задержки поиска. Высокая производительность важна для RAG-систем, где задержка влияет на пользовательский опыт. Pinecone обеспечивает стабильно низкую задержку даже при больших объемах данных.
Стоимость — Pinecone использует модель подписки с оплатой за использование. Стоимость зависит от объема данных и количества запросов. Для небольших проектов Pinecone может быть дорогим, но для крупных проектов стоимость может быть оправдана простотой использования и производительностью. Понимание модели ценообразования важно для планирования бюджета проекта.
Ограничения — Pinecone имеет ограничения по размеру индекса и количеству запросов в зависимости от тарифа. Для очень больших проектов стоимость может быть высокой. Зависимость от облачного провайдера означает, что данные хранятся вне вашей инфраструктуры, что может быть проблемой для некоторых организаций. Ограничения нужно учитывать при выборе решения.
Qdrant: open-source решение с облачным вариантом
Qdrant — это open-source векторная база данных, которая может работать как самостоятельно, так и через облачный сервис Qdrant Cloud. Гибкость выбора между self-hosted и managed решением делает Qdrant привлекательным для различных сценариев использования.
Open-source и self-hosted — Qdrant доступен как open-source решение, которое можно развернуть на собственной инфраструктуре. Это дает полный контроль над данными и инфраструктурой, что важно для организаций с требованиями к безопасности или локализации данных. Self-hosted вариант позволяет оптимизировать затраты для больших объемов данных. Возможность самостоятельного развертывания дает гибкость в выборе инфраструктуры.
Облачный вариант — Qdrant Cloud предоставляет управляемый сервис для тех, кто не хочет управлять инфраструктурой. Облачный вариант сочетает простоту использования managed сервиса с возможностью использования open-source решения. Выбор между self-hosted и cloud вариантом зависит от требований к контролю, безопасности и бюджету. Гибкость выбора — ключевое преимущество Qdrant.
Производительность — Qdrant использует современные алгоритмы индексации и оптимизирован для высокой производительности. Платформа показывает хорошие результаты в бенчмарках и может обрабатывать большие объемы данных с низкой задержкой. Производительность Qdrant сравнима с коммерческими решениями, что делает его привлекательной альтернативой. Высокая производительность важна для production RAG-систем.
Функциональность — Qdrant предоставляет расширенную функциональность: фильтрация по метаданным, гибридный поиск, поддержка различных типов векторов. Расширенная функциональность позволяет создавать более сложные RAG-системы с дополнительными возможностями поиска. Фильтрация по метаданным особенно полезна для корпоративных RAG-систем, где нужно учитывать различные аспекты документов.
Сообщество и поддержка — как open-source проект, Qdrant имеет активное сообщество разработчиков. Документация подробная, есть примеры использования и интеграции с популярными фреймворками. Активное сообщество обеспечивает поддержку и развитие проекта. Поддержка сообщества важна для решения проблем и изучения лучших практик.
FAISS: библиотека от Meta для локального поиска
FAISS (Facebook AI Similarity Search) — это библиотека от Meta для эффективного поиска похожих векторов. FAISS не является полноценной базой данных, а представляет собой библиотеку, которую можно интегрировать в приложения для локального поиска векторов.
Библиотека, а не база данных — FAISS — это библиотека, которая предоставляет алгоритмы поиска векторов, но не управляет хранением данных или инфраструктурой. Разработчики должны самостоятельно управлять хранением векторов, персистентностью, масштабированием. Понимание того, что FAISS — это библиотека, а не база данных, важно для правильного использования. Использование FAISS требует больше технических знаний, но дает больше контроля.
Высокая производительность — FAISS оптимизирован для максимальной производительности поиска. Библиотека использует различные алгоритмы индексации и может использовать GPU для ускорения поиска. Высокая производительность делает FAISS привлекательным для приложений с высокими требованиями к скорости поиска. Оптимизация производительности — ключевое преимущество FAISS.
Локальное выполнение — FAISS работает локально, что означает, что данные не покидают вашу инфраструктуру. Это важно для организаций с требованиями к безопасности или конфиденциальности данных. Локальное выполнение также означает отсутствие затрат на облачные сервисы, что может быть выгодно для больших объемов данных. Контроль над данными — важное преимущество FAISS.
Ограничения — FAISS не предоставляет многие функции полноценных баз данных: персистентность, репликация, масштабирование, управление метаданными. Разработчики должны самостоятельно реализовывать эти функции, что увеличивает сложность разработки. Ограничения FAISS нужно учитывать при выборе решения. Для простых случаев использования FAISS может быть достаточным, но для сложных систем может потребоваться дополнительная разработка.
Использование в RAG — FAISS часто используется в RAG-системах для локального поиска векторов. Интеграция с LangChain и другими фреймворками упрощает использование FAISS в RAG-системах. Для небольших проектов или случаев с требованиями к локальному выполнению FAISS может быть хорошим выбором. Понимание ограничений FAISS помогает правильно использовать его в RAG-системах.
Milvus: масштабируемое open-source решение
Milvus — это open-source векторная база данных, разработанная для работы с большими объемами данных и высокой нагрузкой. Платформа предоставляет полноценную функциональность векторной базы данных с возможностью масштабирования.
Масштабируемость — Milvus разработан для горизонтального масштабирования и может обрабатывать миллиарды векторов. Платформа поддерживает распределенное развертывание и автоматическое масштабирование. Масштабируемость делает Milvus привлекательным для крупных проектов с большими объемами данных. Способность масштабироваться определяет применимость Milvus для различных задач.
Полноценная функциональность — Milvus предоставляет полноценную функциональность векторной базы данных: персистентность, репликация, управление метаданными, фильтрация. Полноценная функциональность позволяет создавать сложные RAG-системы с дополнительными возможностями. Расширенная функциональность важна для корпоративных RAG-систем.
Архитектура — Milvus использует архитектуру с разделением на компоненты: координатор, рабочие узлы, хранилище. Такая архитектура обеспечивает гибкость развертывания и масштабирования. Понимание архитектуры помогает правильно развернуть и настроить Milvus. Архитектура Milvus требует больше знаний для настройки, но обеспечивает больше контроля.
Сообщество и экосистема — Milvus имеет активное сообщество разработчиков и экосистему инструментов. Интеграция с популярными фреймворками и инструментами упрощает использование Milvus в различных проектах. Активное сообщество обеспечивает поддержку и развитие проекта. Экосистема инструментов расширяет возможности использования Milvus.
Сложность настройки — Milvus требует больше знаний для настройки и развертывания по сравнению с managed решениями. Для небольших проектов сложность настройки может быть избыточной, но для крупных проектов она оправдана функциональностью и масштабируемостью. Понимание сложности настройки важно для планирования проекта.
Сравнительная таблица векторных баз данных
Сравнение векторных баз данных по ключевым параметрам помогает выбрать оптимальное решение для конкретной задачи.
| Параметр | Pinecone | Qdrant | FAISS | Milvus |
|---|---|---|---|---|
| Тип решения | Managed cloud | Open-source + Cloud | Библиотека | Open-source |
| Простота использования | Высокая | Средняя | Низкая | Средняя |
| Масштабируемость | Автоматическая | Хорошая | Ограниченная | Отличная |
| Производительность | Высокая | Высокая | Очень высокая | Высокая |
| Стоимость | Высокая | Средняя | Низкая | Средняя |
| Self-hosted | Нет | Да | Да | Да |
| Функциональность | Базовая | Расширенная | Базовая | Полная |
| Сообщество | Коммерческое | Активное | Активное | Активное |
Сравнительная таблица показывает ключевые различия между решениями. Выбор зависит от конкретных требований: масштаба проекта, бюджета, требований к контролю и безопасности, технических возможностей команды. Понимание различий помогает принять обоснованное решение.
Факторы выбора векторной базы данных
Выбор векторной базы данных зависит от множества факторов. Понимание этих факторов помогает выбрать оптимальное решение для конкретной задачи.
Масштаб проекта — объем данных и количество запросов определяют требования к масштабируемости. Для небольших проектов с тысячами векторов подойдет любое решение, для крупных проектов с миллионами векторов нужны масштабируемые решения. Понимание масштаба проекта помогает выбрать подходящее решение. Планирование роста проекта важно для выбора решения, которое сможет масштабироваться.
Бюджет — стоимость использования векторной базы данных зависит от выбранного решения и объема использования. Managed решения удобны, но дороже, open-source решения требуют больше усилий, но могут быть дешевле для больших объемов. Понимание бюджета помогает выбрать решение, которое соответствует финансовым возможностям. Расчет общей стоимости владения важен для принятия решения.
Технические возможности команды — сложность настройки и управления векторной базой данных зависит от технических возможностей команды. Managed решения требуют меньше технических знаний, open-source решения требуют больше экспертизы. Понимание технических возможностей команды помогает выбрать решение, которое команда сможет эффективно использовать. Обучение команды может быть необходимо для использования более сложных решений.
Требования к безопасности и конфиденциальности — некоторые организации имеют требования к локализации данных или запрету на использование облачных сервисов. Self-hosted решения дают полный контроль над данными, managed решения упрощают работу, но данные хранятся у провайдера. Понимание требований к безопасности помогает выбрать подходящее решение. Соответствие требованиям безопасности критично для некоторых организаций.
Производительность — требования к задержке поиска и пропускной способности определяют выбор решения. Для приложений с высокими требованиями к производительности нужны оптимизированные решения. Понимание требований к производительности помогает выбрать решение, которое обеспечивает необходимую скорость. Тестирование производительности важно для подтверждения соответствия требованиям.
Функциональность — требования к дополнительной функциональности, такой как фильтрация по метаданным или гибридный поиск, определяют выбор решения. Некоторые решения предоставляют расширенную функциональность, другие фокусируются на базовом поиске. Понимание требований к функциональности помогает выбрать решение с необходимыми возможностями. Планирование будущих требований важно для выбора решения, которое сможет их удовлетворить.
Рекомендации по выбору
Рекомендации по выбору векторной базы данных помогают принять обоснованное решение на основе конкретных требований.
Для быстрого старта и небольших проектов рекомендуется Pinecone или Qdrant Cloud. Простота использования и отсутствие необходимости настройки инфраструктуры позволяют быстро запустить проект. Managed решения особенно подходят для прототипирования и MVP, где скорость запуска важнее оптимизации затрат. Быстрый старт важен для валидации идеи перед масштабированием.
Для средних проектов с требованиями к контролю рекомендуется Qdrant self-hosted или Milvus. Баланс между функциональностью и сложностью настройки делает эти решения подходящими для большинства production проектов. Self-hosted варианты дают контроль над данными и инфраструктурой, что важно для многих организаций. Баланс функциональности и контроля определяет выбор для средних проектов.
Для крупных проектов с высокими требованиями к масштабированию рекомендуется Milvus. Способность обрабатывать миллиарды векторов и горизонтальное масштабирование делают Milvus подходящим для крупных корпоративных проектов. Инвестиции в настройку и управление оправданы для крупных проектов. Масштабируемость критична для крупных проектов.
Для проектов с требованиями к локальному выполнению рекомендуется FAISS или Qdrant self-hosted. Локальное выполнение обеспечивает контроль над данными и отсутствие затрат на облачные сервисы. Для проектов с особыми требованиями к безопасности локальное выполнение может быть необходимо. Контроль над данными важен для некоторых организаций.
Для проектов с ограниченным бюджетом рекомендуется FAISS или open-source решения. Отсутствие затрат на облачные сервисы делает эти решения привлекательными для проектов с ограниченным бюджетом. Требования к техническим знаниям компенсируются экономией затрат. Бюджетные ограничения определяют выбор для некоторых проектов.
Практические примеры использования
Практические примеры использования различных векторных баз данных помогают понять, как выбрать решение для конкретной задачи.
Пример 1: Стартап с MVP — для быстрого запуска MVP RAG-системы рекомендуется Pinecone. Простота использования позволяет команде фокусироваться на разработке функциональности, а не на настройке инфраструктуры. После валидации идеи можно рассмотреть миграцию на более экономичное решение. Быстрый старт важен для валидации бизнес-модели.
Пример 2: Корпоративный проект с требованиями к безопасности — для корпоративного проекта с требованиями к локализации данных рекомендуется Qdrant self-hosted или Milvus. Self-hosted развертывание обеспечивает контроль над данными и соответствие требованиям безопасности. Инвестиции в настройку оправданы требованиями безопасности. Соответствие требованиям безопасности критично для корпоративных проектов.
Пример 3: Проект с большим объемом данных — для проекта с миллионами векторов рекомендуется Milvus. Способность масштабироваться и обрабатывать большие объемы данных делает Milvus подходящим решением. Инвестиции в настройку и управление оправданы масштабом проекта. Масштабируемость определяет выбор для крупных проектов.
Пример 4: Проект с ограниченным бюджетом — для проекта с ограниченным бюджетом рекомендуется FAISS или Qdrant self-hosted. Отсутствие затрат на облачные сервисы делает эти решения привлекательными. Требования к техническим знаниям компенсируются экономией затрат. Бюджетные ограничения определяют выбор решения.
Заключение
Выбор векторной базы данных для RAG-системы — это важное решение, которое влияет на производительность, масштабируемость и стоимость системы. Pinecone предлагает простоту использования для быстрого старта, Qdrant предоставляет гибкость выбора между self-hosted и cloud вариантами, FAISS обеспечивает максимальную производительность для локального выполнения, Milvus обеспечивает масштабируемость для крупных проектов.
Понимание различий между решениями, требований проекта и факторов выбора помогает принять обоснованное решение. Рекомендации по выбору на основе конкретных сценариев помогают выбрать оптимальное решение. Тестирование выбранного решения перед полноценным внедрением важно для подтверждения соответствия требованиям.
Начните с оценки требований проекта: масштаба, бюджета, технических возможностей команды, требований к безопасности. Выберите решение, которое соответствует требованиям, и протестируйте его на реальных данных. Векторная база данных — это ключевой компонент RAG-системы, правильный выбор которого определяет успех проекта.
Словарь терминов
RAG (Retrieval-Augmented Generation) — архитектура AI-систем, которая комбинирует поиск информации из базы знаний с генерацией ответов языковой моделью.
Embeddings — числовые представления текста, изображений или других данных в виде векторов, которые сохраняют семантическое значение.
Векторная база данных — специализированная система хранения данных, оптимизированная для работы с векторами и поиска похожих векторов.
HNSW (Hierarchical Navigable Small World) — алгоритм индексации для быстрого поиска похожих векторов в векторном пространстве.
IVF (Inverted File Index) — алгоритм индексации, который группирует похожие векторы для ускорения поиска.
Self-hosted — развертывание решения на собственной инфраструктуре с полным контролем над данными и настройками.
Managed service — управляемый сервис, где провайдер управляет инфраструктурой, а пользователь использует API.
Масштабируемость — способность системы обрабатывать растущие объемы данных и нагрузку без снижения производительности.
Персистентность — способность системы сохранять данные между сеансами работы и перезапусками.
Репликация — создание копий данных на нескольких серверах для повышения надежности и производительности.
Метаданные — дополнительная информация о векторах, которая может использоваться для фильтрации результатов поиска.
Гибридный поиск — комбинация векторного поиска и традиционного поиска по ключевым словам для улучшения релевантности результатов.
Задержка (latency) — время между отправкой запроса и получением ответа, критически важный параметр для пользовательского опыта.
Пропускная способность (throughput) — количество запросов, которое система может обработать за единицу времени.
GPU (Graphics Processing Unit) — графический процессор, который может использоваться для ускорения вычислений, включая поиск векторов.

Даниил Акерман
CEO & FOUNDER
Основатель и CEO компании MYPL. Специализируется на разработке комплексных AI-решений и архитектуре корпоративных систем. Эксперт в области машинного обучения и промышленной автоматизации.
t.me/myplnews
Похожие статьи
Все статьи
Телеграмм
Делимся визуально привлекательными фрагментами наших последних веб-проектов.
ВКонтакте
Пишем о интересных технических решениях и вызовах в разработке.
MAX
Демонстрируем дизайнерские элементы наших веб-проектов.
Создаем детальные презентации для наших проектов.
Рассылка
Подпишитесь на нашу рассылку
© 2025 MYPL. Все права защищены.