Техники переранжирования (Reranking): улучшение качества поиска
Техники переранжирования (Reranking): улучшение качества поиска
АВТОР
Даниил Акерман
ДАТА ПУБЛИКАЦИИ
17 декабря 2025 г.
КАТЕГОРИЯ
ML
ВРЕМЯ ЧТЕНИЯ
12 минут
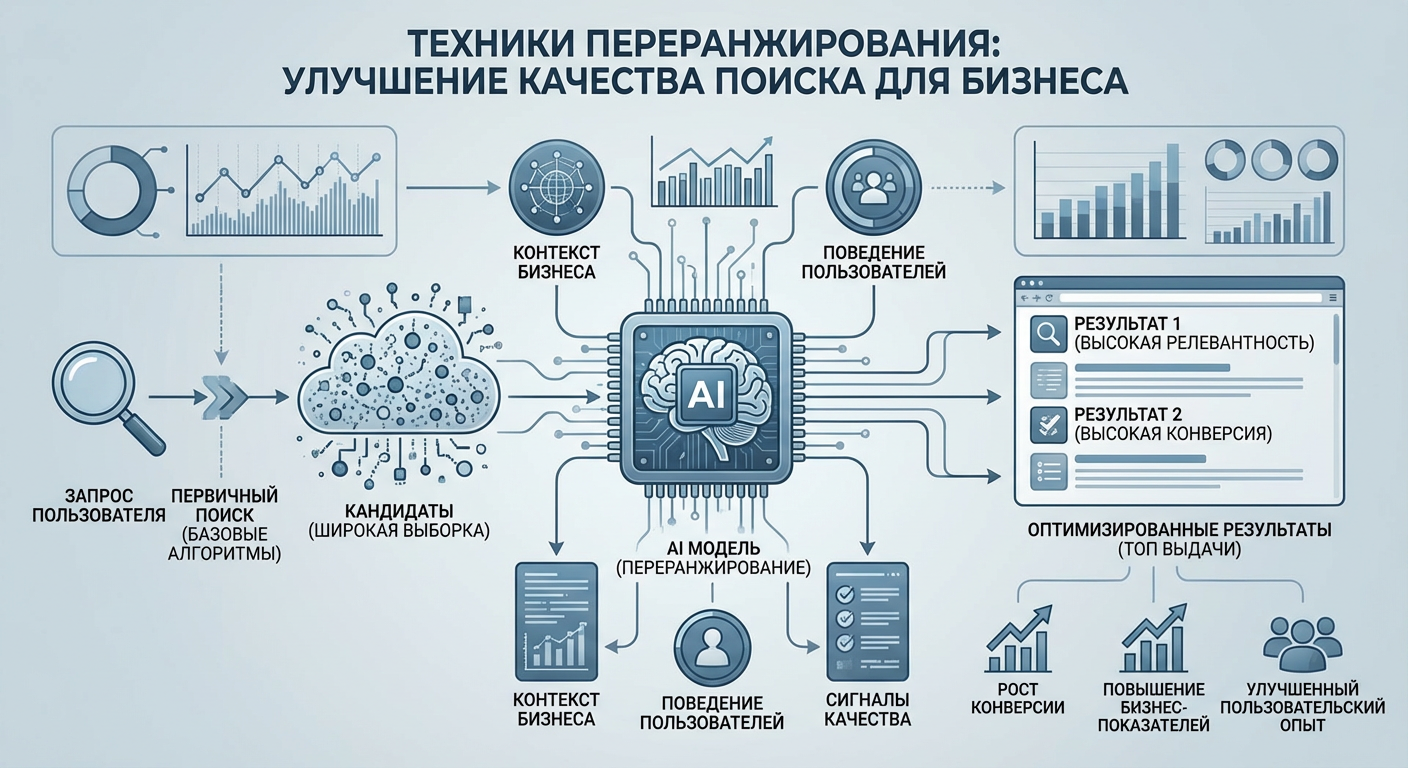
Переранжирование (reranking) — это процесс улучшения качества результатов поиска путем повторной оценки и переупорядочивания документов, найденных на первом этапе поиска. В контексте RAG-систем и поисковых приложений reranking позволяет значительно повысить релевантность результатов, особенно когда начальный поиск возвращает большое количество потенциально релевантных документов. Техники переранжирования стали критически важным компонентом современных AI-систем, работающих с поиском и извлечением информации.
Проблема качества поиска возникает из-за того, что начальный этап поиска (обычно векторный поиск или поиск по ключевым словам) может возвращать документы, которые семантически похожи, но не всегда наиболее релевантны конкретному запросу. Reranking решает эту проблему, используя более сложные модели и методы для точной оценки релевантности каждого документа запросу. Это особенно важно для RAG-систем, где качество извлеченных документов напрямую влияет на качество генерируемых ответов.
В 2025 году техники переранжирования стали стандартом для продвинутых поисковых систем и RAG-приложений. Современные модели reranking могут анализировать контекст запроса и документа, учитывать семантическое сходство, синтаксические особенности, релевантность на разных уровнях детализации. Понимание техник переранжирования критически важно для создания высококачественных поисковых систем и RAG-приложений. В этой статье мы разберем основные техники reranking, их применение в различных системах, методы оценки качества и практические рекомендации по внедрению.
Что такое переранжирование (Reranking)
Переранжирование — это процесс повторной оценки и переупорядочивания результатов поиска с целью улучшения их релевантности запросу. Понимание концепции переранжирования и его места в архитектуре поисковых систем является основой для эффективного использования техник reranking.
Двухэтапный поиск — переранжирование обычно применяется в двухэтапной архитектуре поиска. На первом этапе (retrieval) система быстро находит большое количество потенциально релевантных документов, используя эффективные, но менее точные методы: векторный поиск, поиск по ключевым словам, гибридный поиск. На втором этапе (reranking) система использует более сложные и точные модели для переоценки найденных документов и выбора наиболее релевантных. Двухэтапный подход позволяет балансировать между скоростью поиска и качеством результатов.
Проблема точности начального поиска — начальный этап поиска оптимизирован для скорости и покрытия, но не всегда обеспечивает оптимальное качество. Векторный поиск может находить семантически похожие документы, но не всегда наиболее релевантные конкретному запросу. Поиск по ключевым словам может пропускать релевантные документы, использующие другую терминологию. Reranking решает эти проблемы, используя более точные модели для оценки релевантности.
Улучшение качества результатов — переранжирование позволяет значительно улучшить качество результатов поиска, особенно для сложных запросов или запросов, требующих понимания контекста. Модели reranking могут анализировать более глубокие семантические связи, учитывать контекст запроса и документа, оценивать релевантность на разных уровнях. Это приводит к тому, что наиболее релевантные документы оказываются в начале списка результатов.
Компромисс между скоростью и качеством — переранжирование требует дополнительных вычислений, что увеличивает время ответа системы. Однако применение reranking только к небольшому подмножеству документов (например, топ-100 или топ-1000) позволяет балансировать между скоростью и качеством. Понимание компромиссов помогает эффективно использовать reranking в практических системах.
Интеграция с RAG-системами — в RAG-системах reranking критически важен для качества извлеченных документов, которые затем используются для генерации ответов. Качественное переранжирование позволяет извлекать наиболее релевантные документы, что улучшает качество и точность генерируемых ответов. Reranking стал стандартным компонентом продвинутых RAG-систем.
Типы моделей переранжирования
Существуют различные типы моделей переранжирования, каждая из которых имеет свои особенности и преимущества. Понимание различных типов моделей помогает выбрать подходящий подход для конкретной задачи.
Cross-encoder модели — cross-encoder модели принимают на вход пару (запрос, документ) и выдают оценку релевантности. Эти модели могут анализировать взаимодействие между запросом и документом на глубоком уровне, что позволяет точно оценивать релевантность. Cross-encoder модели обычно показывают лучшее качество, но требуют больше вычислений, так как для каждого документа нужно выполнять отдельный forward pass через модель. Cross-encoder модели особенно эффективны для reranking небольшого количества документов.
Bi-encoder модели — bi-encoder модели создают отдельные векторные представления для запроса и документа, а затем вычисляют сходство между векторами. Эти модели быстрее, так как векторы запроса и документов можно предвычислить и кэшировать. Однако bi-encoder модели обычно показывают немного худшее качество по сравнению с cross-encoder моделями, так как не могут анализировать взаимодействие между запросом и документом на глубоком уровне. Bi-encoder модели подходят для reranking большого количества документов.
Гибридные подходы — гибридные подходы комбинируют различные типы моделей для баланса между качеством и скоростью. Например, можно использовать bi-encoder для быстрого отбора топ-100 документов, а затем применить cross-encoder для точного переранжирования топ-20. Гибридные подходы позволяют оптимизировать баланс между качеством и производительностью для конкретных требований системы.
Специализированные модели reranking — существуют модели, специально обученные для задачи переранжирования. Эти модели оптимизированы для оценки релевантности пар запрос-документ и показывают отличные результаты на различных типах запросов и документов. Специализированные модели reranking стали стандартом для высококачественных поисковых систем.
Адаптация общих моделей — общие языковые модели (например, BERT, RoBERTa) могут быть адаптированы для задачи переранжирования через fine-tuning на данных с оценками релевантности. Fine-tuning позволяет адаптировать модель под специфические требования: тип документов, домен, стиль запросов. Адаптация общих моделей может быть эффективной альтернативой специализированным моделям.
Методы обучения моделей reranking
Обучение моделей переранжирования требует данных с оценками релевантности и подходящих методов обучения. Понимание методов обучения помогает эффективно создавать и улучшать модели reranking.
Обучение на размеченных данных — модели reranking обучаются на данных, где для каждой пары (запрос, документ) есть оценка релевантности: бинарная (релевантен/не релевантен) или числовая (степень релевантности). Размеченные данные могут быть получены из различных источников: клики пользователей, экспертные оценки, оценки релевантности от других систем. Качество размеченных данных критически важно для качества обученной модели.
Обучение на парах — модели reranking часто обучаются на парах документов, где один документ более релевантен запросу, чем другой. Модель учится различать более и менее релевантные документы, что позволяет ей ранжировать документы по релевантности. Обучение на парах особенно эффективно, когда сложно получить точные числовые оценки релевантности.
Обучение на списках — некоторые методы обучения работают со списками документов для запроса, где известен правильный порядок документов по релевантности. Модель учится ранжировать документы в правильном порядке. Обучение на списках позволяет модели учитывать относительную релевантность документов, что важно для задачи ранжирования.
Метрики обучения — обучение моделей reranking использует метрики, специфичные для задачи ранжирования: NDCG (Normalized Discounted Cumulative Gain), MRR (Mean Reciprocal Rank), MAP (Mean Average Precision). Эти метрики оценивают качество ранжирования, а не только точность классификации. Использование правильных метрик критически важно для обучения качественных моделей reranking.
Transfer learning и fine-tuning — предобученные языковые модели могут быть адаптированы для задачи переранжирования через fine-tuning на данных с оценками релевантности. Fine-tuning позволяет использовать знания, полученные при предобучении, и адаптировать их под конкретную задачу. Transfer learning особенно эффективен, когда доступно ограниченное количество размеченных данных.
Применение reranking в RAG-системах
Reranking играет критически важную роль в RAG-системах, где качество извлеченных документов напрямую влияет на качество генерируемых ответов. Понимание применения reranking в RAG-системах помогает эффективно использовать его для улучшения качества системы.
Улучшение извлечения документов — в RAG-системах reranking применяется после начального этапа извлечения документов для выбора наиболее релевантных документов для контекста. Качественное переранжирование позволяет извлекать документы, которые наиболее точно отвечают на запрос пользователя, что улучшает качество генерируемых ответов. Reranking особенно важен для сложных запросов или запросов, требующих точной информации.
Оптимизация контекста для LLM — качественное переранжирование позволяет оптимизировать контекст, передаваемый языковой модели для генерации ответа. Выбор наиболее релевантных документов уменьшает шум в контексте и позволяет модели генерировать более точные и релевантные ответы. Оптимизация контекста критически важна для качества RAG-систем.
Снижение галлюцинаций — качественное извлечение релевантных документов через reranking помогает снизить галлюцинации в генерируемых ответах. Когда модель получает точную и релевантную информацию, она с меньшей вероятностью будет генерировать неправильную информацию. Reranking является важным компонентом систем контроля качества в RAG-приложениях.
Баланс между количеством и качеством документов — reranking позволяет балансировать между количеством извлеченных документов и их качеством. Система может извлечь больше документов на начальном этапе для обеспечения покрытия, а затем использовать reranking для выбора наиболее релевантных. Это позволяет оптимизировать баланс между полнотой и точностью извлечения.
Интеграция с векторным поиском — reranking часто применяется после векторного поиска для улучшения качества результатов. Векторный поиск обеспечивает быстрое извлечение семантически похожих документов, а reranking улучшает их релевантность конкретному запросу. Комбинация векторного поиска и reranking стала стандартом для высококачественных RAG-систем.
Методы оценки качества reranking
Оценка качества переранжирования требует использования метрик, специфичных для задачи ранжирования. Понимание методов оценки помогает эффективно измерять и улучшать качество reranking.
NDCG (Normalized Discounted Cumulative Gain) — NDCG является одной из наиболее популярных метрик для оценки качества ранжирования. Метрика учитывает позицию релевантных документов в списке результатов, придавая больше веса документам, находящимся выше в списке. NDCG нормализована, что позволяет сравнивать результаты на разных запросах. NDCG особенно полезна для оценки качества reranking, так как она учитывает порядок документов.
MRR (Mean Reciprocal Rank) — MRR измеряет среднее значение обратного ранга первого релевантного документа по всем запросам. Метрика особенно полезна для задач, где важно найти хотя бы один релевантный документ. MRR проста в вычислении и интерпретации, что делает ее популярной метрикой для оценки качества поиска.
MAP (Mean Average Precision) — MAP измеряет среднюю точность по всем запросам, учитывая позиции всех релевантных документов. Метрика особенно полезна для задач, где важно найти все релевантные документы. MAP учитывает как полноту, так и точность результатов, что делает ее комплексной метрикой оценки качества.
Оценка на реальных данных — оценка качества reranking на реальных данных пользователей позволяет понять, насколько хорошо система работает в практических условиях. Клики пользователей, время на странице, обратная связь могут использоваться как сигналы качества результатов. Оценка на реальных данных критически важна для понимания практической эффективности системы.
A/B тестирование — A/B тестирование позволяет сравнивать различные подходы к reranking в реальных условиях. Сравнение различных моделей или параметров на реальных пользователях помогает выбрать оптимальный подход. A/B тестирование является важным инструментом для оптимизации качества reranking в продакшене.
Оптимизация производительности reranking
Производительность reranking может быть критическим фактором для практических систем, особенно при работе с большими объемами данных. Понимание методов оптимизации помогает эффективно использовать reranking в масштабируемых системах.
Ограничение количества документов для reranking — применение reranking только к небольшому подмножеству документов (например, топ-100 или топ-1000) позволяет балансировать между качеством и производительностью. Выбор оптимального количества документов для reranking зависит от требований к качеству и производительности системы. Ограничение количества документов является простым и эффективным способом оптимизации производительности.
Кэширование результатов — результаты reranking для часто встречающихся запросов могут быть кэшированы для ускорения ответа системы. Кэширование особенно эффективно для запросов, которые повторяются часто или имеют стабильные результаты. Кэширование позволяет значительно улучшить производительность без потери качества.
Параллельная обработка — reranking различных документов может выполняться параллельно для ускорения обработки. Параллельная обработка особенно эффективна при использовании GPU или распределенных систем. Оптимизация параллельной обработки может значительно улучшить производительность reranking.
Использование более быстрых моделей — выбор более быстрых моделей reranking (например, bi-encoder вместо cross-encoder) может улучшить производительность при приемлемом качестве. Понимание компромиссов между качеством и скоростью помогает выбрать подходящую модель для конкретных требований. Использование более быстрых моделей может быть эффективным способом оптимизации производительности.
Оптимизация инференса — оптимизация процесса инференса модели (например, использование quantization, pruning, оптимизированных библиотек) может улучшить производительность reranking. Оптимизация инференса позволяет ускорить обработку без изменения архитектуры модели. Понимание методов оптимизации инференса помогает эффективно улучшать производительность.
Практические рекомендации по внедрению reranking
Внедрение reranking в практические системы требует понимания различных аспектов: выбора моделей, настройки параметров, интеграции с существующими системами. Понимание практических рекомендаций помогает эффективно внедрять reranking.
Выбор подходящей модели — выбор подходящей модели reranking зависит от различных факторов: требования к качеству, ограничения производительности, тип документов и запросов. Специализированные модели reranking обычно показывают лучшее качество, но могут требовать больше ресурсов. Общие модели могут быть адаптированы через fine-tuning под конкретные требования. Понимание компромиссов помогает выбрать подходящую модель.
Настройка количества документов для reranking — выбор количества документов для reranking требует баланса между качеством и производительностью. Большее количество документов может улучшить качество, но увеличивает время обработки. Меньшее количество документов ускоряет обработку, но может снизить качество. Экспериментирование с различными значениями помогает найти оптимальный баланс.
Интеграция с существующими системами — интеграция reranking с существующими поисковыми системами требует понимания архитектуры системы и точек интеграции. Reranking может быть интегрирован как отдельный сервис или как часть существующего pipeline поиска. Понимание архитектуры помогает эффективно интегрировать reranking.
Мониторинг и оценка качества — регулярный мониторинг качества reranking на реальных данных позволяет выявлять проблемы и улучшать систему. Использование метрик качества, обратной связи пользователей, A/B тестирования помогает постоянно улучшать качество reranking. Мониторинг критически важен для поддержания высокого качества системы.
Итеративное улучшение — улучшение качества reranking — это итеративный процесс, требующий постоянного экспериментирования и оптимизации. Экспериментирование с различными моделями, параметрами, методами обучения помогает находить улучшения. Итеративное улучшение позволяет постепенно повышать качество reranking.
Заключение
Техники переранжирования (reranking) стали критически важным компонентом современных поисковых систем и RAG-приложений. Переранжирование позволяет значительно улучшить качество результатов поиска, особенно для сложных запросов или запросов, требующих понимания контекста. Понимание различных типов моделей reranking, методов обучения, оценки качества и оптимизации производительности помогает эффективно использовать переранжирование в практических системах.
В RAG-системах reranking играет особенно важную роль, так как качество извлеченных документов напрямую влияет на качество генерируемых ответов. Качественное переранжирование позволяет извлекать наиболее релевантные документы, оптимизировать контекст для языковой модели, снижать галлюцинации. Reranking стал стандартным компонентом продвинутых RAG-систем.
Выбор подходящего подхода к reranking зависит от конкретных требований: качества, производительности, типа документов и запросов. Понимание компромиссов между различными подходами помогает выбрать оптимальное решение. Регулярный мониторинг и итеративное улучшение позволяют постоянно повышать качество reranking и обеспечивать высокое качество поисковых систем и RAG-приложений.
Словарь терминов
Reranking (переранжирование) — процесс повторной оценки и переупорядочивания результатов поиска с целью улучшения их релевантности запросу.
Cross-encoder — тип модели переранжирования, которая принимает на вход пару (запрос, документ) и выдает оценку релевантности, анализируя взаимодействие между запросом и документом.
Bi-encoder — тип модели переранжирования, которая создает отдельные векторные представления для запроса и документа, а затем вычисляет сходство между векторами.
NDCG (Normalized Discounted Cumulative Gain) — метрика для оценки качества ранжирования, учитывающая позицию релевантных документов в списке результатов.
MRR (Mean Reciprocal Rank) — метрика, измеряющая среднее значение обратного ранга первого релевантного документа по всем запросам.
MAP (Mean Average Precision) — метрика, измеряющая среднюю точность по всем запросам, учитывая позиции всех релевантных документов.
Двухэтапный поиск — архитектура поиска, где на первом этапе быстро находятся потенциально релевантные документы, а на втором этапе применяется переранжирование для выбора наиболее релевантных.
Retrieval — первый этап поиска, на котором система быстро находит потенциально релевантные документы.
Fine-tuning — процесс дообучения предобученной модели на данных для конкретной задачи.
Transfer learning — использование знаний, полученных при решении одной задачи, для решения другой задачи.

Даниил Акерман
CEO & FOUNDER
Основатель и CEO компании MYPL. Специализируется на разработке комплексных AI-решений и архитектуре корпоративных систем. Эксперт в области машинного обучения и промышленной автоматизации.
t.me/myplnews
Похожие статьи
Все статьи
Телеграмм
Делимся визуально привлекательными фрагментами наших последних веб-проектов.
ВКонтакте
Пишем о интересных технических решениях и вызовах в разработке.
MAX
Демонстрируем дизайнерские элементы наших веб-проектов.
Создаем детальные презентации для наших проектов.
Рассылка
Подпишитесь на нашу рассылку
© 2025 MYPL. Все права защищены.