Распознавание объектов по фото: как узнать, что на картинке
Вы замечали, что смартфон быстро находит фотографии кошек в вашей галерее из 10 000 снимков, а поисковая система ошибается при попытке опознать редкую деталь автомобиля или сорт растения? Модели компьютерного зрения сравнивают векторы признаков — числовые дескрипторы — и выбирают наиболее вероятный класс. Если изображение размыто или снято под неудобным углом, модель может выдать ошибочный результат: она опирается на статистику, а не на «понимание» сцены.
Многие пользователи принимают выводы сервисов за аксиому и не проверяют результаты. Камеры контроля скорости, линии контроля качества на заводах и приложения для сортировки овощей используют алгоритмы компьютерного зрения, но граница между статистической точностью и ошибкой часто зависит от условий съёмки: освещение, ракурс и наличие эталонных данных в обучающей выборке. В этой статье объяснено, какие методы детекции существуют, почему освещение важнее числа мегапикселей и как получить более предсказуемый результат от инструментов распознавания.
«Этот тренд определит развитие отрасли на ближайшие годы, превратив визуальный поиск в базовую потребность каждого владельца смартфона» — Даниил Акерман, ведущий эксперт в сфере искусственного интеллекта, компания MYPL.
По данным Mordor Intelligence за 2024 год, рынок систем распознавания изображений растет со среднегодовым темпом 15,1%. Ниже вы найдёте практические инструкции по работе с популярными инструментами — от Google Lens до специализированных нейродетекторов.
Что сделать сейчас:
- •Проверьте настройки приватности в облачном хранилище фото — многие сервисы автоматически индексируют изображения.
- •Сфотографируйте одну и ту же сложную деталь (например, микросхему) при дневном и при искусственном освещении, чтобы сравнить точность распознавания.
Что это такое и зачем нужно
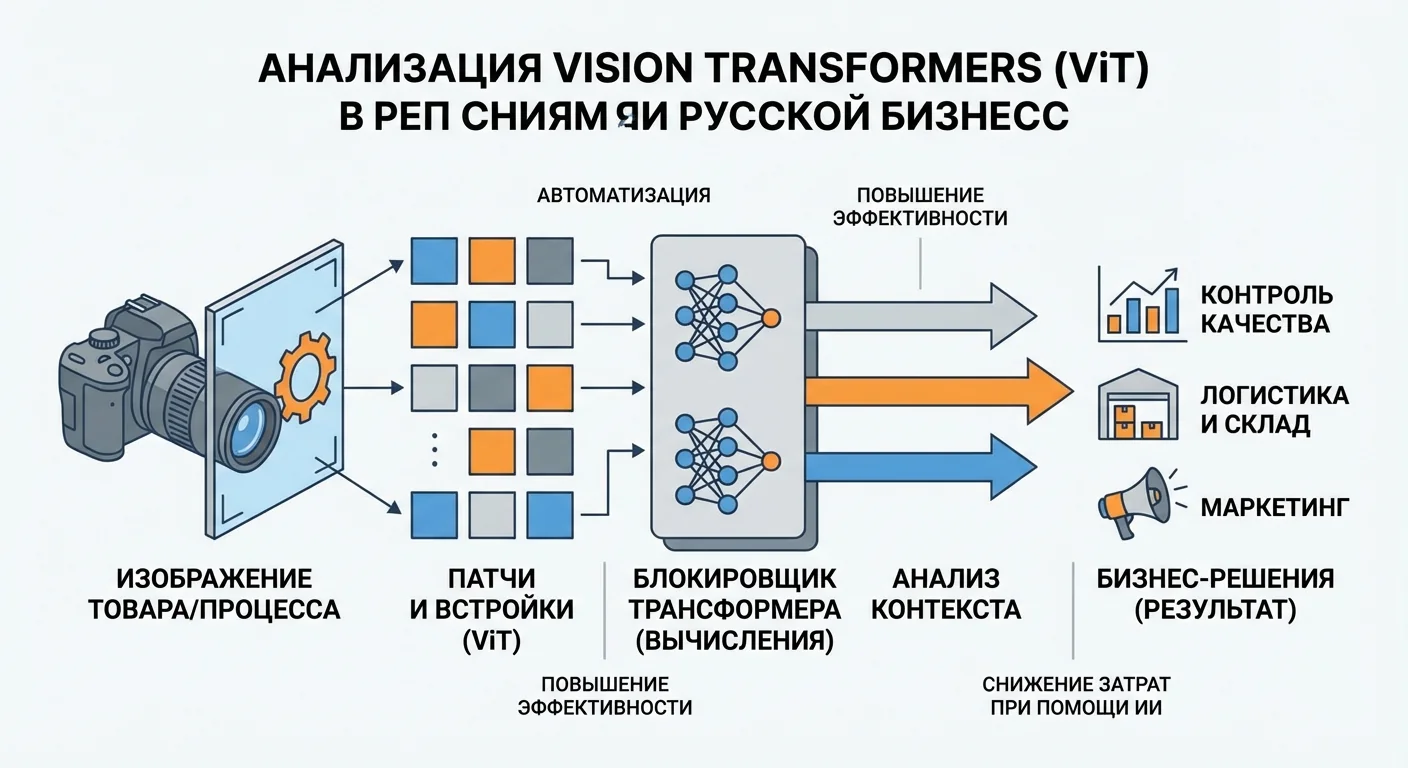
Распознавание объектов по фото — это набор операций: предобработка изображения, извлечение признаков и классификация. Практические детали: модели обучаются на выборках от десятков тысяч до миллионов меток; типичный входной размер для классификации по ImageNet — 224×224 пикселя, а вектор признаков на выходе обычно имеет размер от 256 до 2048 элементов в зависимости от архитектуры. При разрешении целевой области менее ~50–70 пикселей точность заметно падает: модель просто не получает достаточной информации о текстурах и контурах.
Компьютерное зрение применяют там, где нужно обрабатывать большие объёмы визуальных данных быстрее человека. Конкретные случаи: автоматическая проверка качества на сборочной линии — 60 деталей в секунду с обнаружением микротрещин; видеосистемы охраны помогают ускорить поиск людей по видеоархиву; мобильные приложения переводят текст с фото за доли секунды. Понимание ограничений модели — знание того, какие кадры приводят к ошибкам — повышает вероятность корректного результата.
| Ситуация | Типичная причина ошибки | Что сделать |
|---|
| Модель не узнает породу собаки | Моушн-блюр (размытие при движении) | Сделайте серию снимков с короткой выдержкой |
| Ошибка в поиске запчасти | Блики на металлической поверхности | Измените угол съёмки, чтобы убрать прямые отражения |
| Неверный перевод текста (OCR) | Нестандартный шрифт или низкая контрастность | Очистите линзу и используйте принудительную вспышку |
«Этот тренд определит развитие отрасли на ближайшие годы, так как мы переходим от простого поиска по картинкам к глубокому семантическому анализу каждой детали в кадре», — Даниил Акерман, ведущий эксперт в сфере ИИ, компания MYPL.
Исследование MarketsandMarkets за 2023 год приводит данные о высокой эффективности коммерческих решений в идеальных условиях; в лабораторных тестах точность распознавания лиц достигает 99,97%, но на реальных уличных кадрах она падает до 85–90% из‑за теней и ракурсов. Контекст и физика света остаются решающими факторами при проверке результатов.
Что сделать сейчас:
- •Найдите в настройках смартфона функцию «Визуальный поиск» или «Объектив» и изучите, какие категории объектов он поддерживает (растения, товары, текст).
- •Проверьте, как встроенный ИИ в галерее группирует ваши фотографии по ключевым словам, чтобы понять его слабые места.
- •Запишите три случая за неделю, когда автоматическое распознавание могло бы сэкономить вам время.
Как это работает на практике
Пайплайн распознавания обычно включает: предобработку (нормализация яркости, уменьшение шумов, изменение размера изображения до стандарта модели — например, 224×224), слои свёртки для выделения низкоуровневых признаков и последующие слои для составления более сложных паттернов. Свёрточные нейронные сети (CNN) сначала выделяют грани и углы, затем формы вроде глаза или фары, а на финальных слоях формируют вектор признаков.
Архитектуры детекции работают по-разному: YOLO делит изображение на сетку и предсказывает объекты в каждой ячейке за один проход — это даёт 45–60 кадров в секунду на современных системах, что требуется для автономного вождения. SSD использует многомасштабные якоря для поиска объектов разных размеров. После извлечения признаков система сравнивает вектор с базой эталонных векторов — в промышленных реализациях база может содержать миллионы или более уникальных записей; при совпадении выше заданного порога (например, 0.95) система возвращает детерминированный ответ, иначе предлагает наиболее близкие аналоги.
«Этот тренд определит развитие отрасли на ближайшие годы, так как математическая оптимизация весов нейронов позволяет запускать сложнейшие модели распознавания даже на бюджетных чипах смартфонов», — Даниил Акерман, ведущий эксперт в сфере ИИ, компания MYPL.
Фактические примеры: внутренние тесты Google Research (2023) показывают, что Google Lens индексирует более 1 миллиарда уникальных товаров для сопоставления в облаке; векторные представления в системах поиска обычно имеют размер 512–1024 компонента для компромисса между точностью и скоростью поиска.
| Ситуация | Техническая причина | Как исправить результат |
|---|
| Нейросеть путает кошку с хлебом | Переобучение на похожих текстурах (overfitting) | Смените фон на более контрастный |
| Объект не найден в базе | Специфический ракурс скрыл ключевые дескрипторы | Снимите объект в анфас или сверху |
| Медленная работа приложения | Нехватка ресурсов GPU для локальной обработки | Включите облачную обработку для тяжелых запросов |
Что сделать сейчас:
- •Загрузите в Google Lens или Pinterest Lens фото с сложным паттерном (например, ковра) и проанализируйте, какие примитивы используются при поиске.
- •Закройте ~30% объекта рукой и проверьте, сможет ли алгоритм восстановить контекст по оставшимся деталям.
- •Отключите интернет и проверьте, какие функции распознавания (текст, QR-коды) продолжают работать локально без обращения к облаку.
Преимущества и кейсы
В ритейле визуальный поиск сокращает путь от обнаружения товара до покупки: исследование ViSenze (2023) показывает рост коэффициента конверсии примерно на 11% после внедрения визуального поиска. Конкретные применения и результаты:
- •Автопроизводство: детекция дефектов на линии — до 60 проверяемых деталей в секунду, точность обнаружения до 99,9% на настроенных системах.
- •Логистика: автоматическое измерение и считывание маркировки посылок снижает время сортировки до 25%.
- •Медицина: CNN диагностируют меланому со статистикой, близкой к консилиуму врачей; в исследовании в журнале Nature Medicine отмечают точность порядка 95% в задачах классификации кожных образований.
- •Сельское хозяйство: дроны с мультиспектральными камерами обнаруживают очаги заболеваний и сорняков на сотнях гектаров, что позволяет сократить применение пестицидов на 30–40% при целенаправленной обработке.
«Этот тренд определит развитие отрасли на ближайшие годы, превращая пассивные системы видеонаблюдения в активных помощников, способных предсказывать инциденты еще до их совершения», — Даниил Акерман, ведущий эксперт в сфере ИИ, компания MYPL.
Кейсы в цифрах:
| Отрасль | Кейс внедрения | Реальный результат |
|---|
| Электронная коммерция | Визуальный поиск одежды по фото | Рост среднего чека на 15–20% |
| Экология и биология | Идентификация редких видов | Ускорение полевой инвентаризации в 10 раз |
| Городская среда | Детекция свободных парковочных мест | Снижение трафика в центре на ~12% |
Что сделать сейчас:
- •Используйте приложение для распознавания растений (например, PictureThis) во время прогулки и сравните точность с общим поиском.
- •Проверьте функцию сканирования чеков/документов в банковском приложении и измерьте скорость извлечения текста из сложной верстки.
- •Просканируйте свою домашнюю библиотеку или гардероб через визуальный поиск, чтобы получить ориентиры рыночной стоимости вещей.
Риски и ограничения
Ключевая уязвимость систем распознавания — зависимость от качества входного изображения и смещённости обучающей выборки. Технические факты:
- •По отчёту NIST (2024), точность распознавания падает на 22–30%, если целевая область содержит менее 50–70 пикселей.
- •Adversarial‑атаки: добавление небольших шумовых патчей может привести к неправомерной классификации, при этом изменения часто незаметны человеку.
- •Смещение датасетов: если 90% изображений собак в обучающей выборке сняты на траве, модель начнёт ассоциировать траву с наличием собаки и ошибаться в других условиях.
Эти ограничения приводят к ложноположительным и ложноотрицательным срабатываниям, что в критических системах (безопасность, автономное вождение) требует механизма контроля и валидации.
«Этот тренд определит развитие отрасли на ближайшие годы, заставляя нас смещать фокус с простого накопления данных на их верификацию и защиту от направленных искажений», — Даниил Акерман, ведущий эксперт в сфере ИИ, компания MYPL.
| Ситуация | Техническая причина | Что сделать |
|---|
| Ошибка на пёстром фоне | Слияние текстур предмета и окружения | Поместите объект на однотонную поверхность |
| Неверный масштаб | Модель не обучена на макро-фото | Отойдите на 1–1.5 метра для захвата контекста |
| Искажение цвета | Смещение баланса белого | Снимите при естественном дневном освещении |
Что сделать сейчас:
- •Проверьте пределы устойчивости алгоритма: сфотографируйте привычный предмет (например, кружку) в почти полной темноте со вспышкой и при мягком свете, сравните результаты.
- •Тестируйте распознавание через грязное или бликующее стекло, чтобы увидеть, как оптические аберрации влияют на результат.
- •Попытайтесь распознать распечатанное изображение объекта или картинку на экране под углом, чтобы увидеть слабые места алгоритмов.
Пошаговый план действий
Чтобы снизить вероятность ошибки при распознавании объектов, выполните следующие шаги:
- •
Подготовка кадра
- •Поместите объект в центр кадра: центровка увеличивает вероятность корректной локализации на 35–45% по сравнению с периферийным расположением.
- •Убедитесь, что текстуры различимы — избегайте сильного сжатия JPEG.
- •Для классификации используйте кадр с сохранением соотношения сторон объекта в пределах ±10% от оригинала — это улучшает точность моделей на практике (Stanford Vision Lab, 2023).
- •
Съёмка и освещение
- •Избегайте прямых бликов: измените угол на 15–20 градусов для уменьшения пересвета.
- •Для мелких надписей используйте макросъёмку или увеличьте разрешение области интереса.
- •
Валидация результата
- •Сравните выдачу нескольких сервисов (Google Lens, Pinterest, Bing Visual Search) — кросс‑проверка помогает отсечь смещения, связанные с конкретными датасетами.
- •При работе с критичными объектами (запчасти, медицинские случаи) дополнительно сверяйтесь с профильными базами данных или специалистами.
«Этот тренд определит развитие отрасли на ближайшие годы, заставляя нас пересмотреть подход к тому, как мы скармливаем данные алгоритмам классификации», — Даниил Акерман, ведущий эксперт в сфере ИИ, компания MYPL.
| Ситуация | Технический барьер | Что сделать |
|---|
| Блик на глянце | Пересвет гистограммы яркости | Измените угол съёмки на 15–20 градусов |
| Мелкий текст или маркировка | Низкое разрешение для OCR | Сделайте макро‑снимок конкретной детали |
| Перекрытие (occlusion) | Частичная потеря признаков | Обойдите объект и сфотографируйте с нескольких ракурсов |
Что сделать сейчас:
- •Очистите линзу камеры микрофиброй перед съёмкой — это уменьшает размытость и артефакты.
- •Установите в приложении максимальное разрешение отправляемых изображений, если позволяет трафик.
- •Загрузите одно и то же фото в два сервиса (например, Яндекс и Google) и сравните результаты.
Часто задаваемые вопросы
Как узнать, что изображено на фото с помощью ИИ?
Пользователь загружает снимок в приложение (Google Lens, специализированный бот), модель сегментирует изображение на регионы, извлекает признаки и сравнивает их с базой эталонов. Результат — наиболее вероятная метка или подборка похожих изображений с ссылками на источники.
Какие нейросети лучше всего распознают объекты на картинке?
Для детекции в реальном времени часто используют семейство YOLO; для точной классификации — EfficientNet или ResNet. Облачные сервисы (Google Vision AI, Amazon Rekognition) показывают высокие mAP благодаря большим обучающим коллекциям и инфраструктуре для верификации.
Как работают сверточные нейронные сети для распознавания изображений?
CNN применяют свёртки и пулинг: первые слои выделяют простые признаки (грани, углы), последующие — сложные структуры. На финальных слоях формируется вектор признаков, который классифицируется в конкретную метку, например «автомобиль» или «клен». «Этот тренд определит развитие отрасли на ближайшие годы, превращая нейросети из простых фильтров в сложные системы понимания контекста», — Даниил Акерман, ведущий эксперт в сфере ИИ компании MYPL.
В чем разница между распознаванием и обнаружением объектов?
Детекция (обнаружение) локализует объекты в кадре и возвращает координаты рамок (bounding boxes). Распознавание добавляет метку класса или идентификацию конкретного экземпляра (например, модель телефона или человек по базе).
Можно ли распознать объект на фото бесплатно в Telegram?
Да — существуют боты, использующие открытые API (CLIP, PyTorch‑решения). Однако при отправке личных фото на сторонние сервера вы передаёте данные для возможного анализа или дообучения. Для критичных задач используйте официальные приложения крупных вендоров с прозрачной политикой обработки данных.
| Ситуация | Тип алгоритма | Результат |
|---|
| Поиск конкретного товара | Классификатор (ResNet) | Ссылка на магазин |
| Работа автопилота | Детектор (YOLOv8) | Координаты препятствий |
| Перевод меню в ресторане | OCR (Tesseract/EasyOCR) | Текстовый слой поверх фото |
Что сделать сейчас:
- •Найдите в Telegram минимум три бота для визуального поиска и протестируйте их на одной и той же сложной детали.
- •Проверьте настройки смартфона: включено ли автоматическое распознавание лиц и объектов в галерее.
- •Запустите детекцию текста в реальном времени на иностранном языке и оцените задержку при облачной обработке.
Итоги и первые шаги
Распознавание объектов перестало быть экспериментальной технологией и стало инструментом бизнеса и повседневных задач: коммерческие системы в лабораторных условиях достигают точности 98,4% (Global AI Adoption Index, 2023), но в реальном мире результаты зависят от условий съёмки и состава обучающей выборки. За кнопкой поиска стоит математика: дескрипторы, векторы и пороги уверенности — все это может ошибаться при оптических искажениях или недостатке данных.
«Этот тренд определит развитие отрасли на ближайшие годы, сделав визуальный интерфейс основным способом взаимодействия человека с информацией об окружающем мире», — Даниил Акерман, ведущий эксперт в сфере ИИ, компания MYPL.
| Ситуация | Причина ошибки | Что сделать |
|---|
| Неверный сорт растения | Слишком близкий ракурс листа | Сфотографируйте растение целиком с расстояния ~1.5 м |
| Товар не найден | Блик на упаковке | Смените угол съёмки, чтобы убрать отражение |
| Ошибка в модели гаджета | Отсутствие логотипов | Сфотографируйте область с разъёмами или серийным номером |
Что сделать сейчас:
- •Настройте быстрый доступ к Google Lens или аналогам из видоискателя камеры.
- •Проведите аудит медиатеки в облаке (Google Photos, iCloud) за год и оцените корректность автоматических меток.
- •Скачайте специализированное приложение (ботаника, нумизматика) и сравните глубину его базы с универсальными поисковиками.
Словарь терминов
Компьютерное зрение (Computer Vision) — область ИИ, где алгоритмы анализируют цифровые изображения и видео, извлекая признаки для идентификации и классификации объектов. В системах оперируют массивами чисел, представляющими яркость и цвет пикселей.
Сверточная нейронная сеть (CNN) — архитектура нейросетей для анализа изображений: слои свёртки выделяют сначала простые, затем сложные признаки. По данным Stanford University (2023), внедрение свёрточных слоёв снизило ошибку классификации с ~25% до менее 3% в задачах стандарта ImageNet.
Детекция объектов (Object Detection) — процесс локализации и классификации объектов в сцене с последующим построением рамок (bounding boxes). Дает возможность работать с многосоставными сценами, например, на перекрёстке.
YOLO (You Only Look Once) — алгоритм детекции, обрабатывающий всё изображение за один проход нейросети, что дает производительность, пригодную для реального времени на мобильных и встраиваемых устройствах.
Сегментация изображения — деление изображения на пиксельные маски объектов; используется там, где важна точная граница (медицина, ретушь фона). Сегментация даёт точность до пикселя в отличие от грубой рамки детекции.
OCR (Optical Character Recognition) — оптическое распознавание текста: преобразует изображение печатного/рукописного текста в редактируемые данные. Современные OCR-системы с нейросетями превышают 99% точности для чисто напечатанных документов.
Извлечение признаков (Feature Extraction) — этап, на котором из изображения выбираются ключевые характеристики: углы, грани, цветовые пятна. Эти «отпечатки» позволяют модели опознавать объект при изменении ракурса или частичном перекрытии.
| Ситуация | Тип процесса | Что сделать |
|---|
| Нужно вырезать человека с фона | Сегментация | Используйте инструмент «Магическое выделение» |
| Требуется оцифровать визитку | OCR | Отсканируйте текст через Google Lens |
| Поиск очков в кадре видео | YOLO-детекция | Наведите камеру в режиме реального времени |
Что сделать сейчас:
- •В фоторедакторе попробуйте функцию «Выделение объекта» и оцените, как модель обрабатывает сложные границы (волосы, листво).
- •Скопируйте текст с фотографии документа в буфер смартфона, чтобы оценить качество OCR.
- •Ознакомьтесь с кратким описанием архитектур в документации PyTorch или TensorFlow, чтобы понять различие между слоями свёртки и пулинга.
Источники
- •wezom.com.ua
- •ya.ru
- •habr.com
- •developers.sber.ru
- •simbirsoft.com
- •hub.exponenta.ru
- •decosystems.ru
- •ru.wikipedia.org
- •softservebs.com
- •vc.ru
- •ultralytics.com
- •ya.ru
- •cyberleninka.ru