Промты для нейросети: полный гайд с примерами для любых задач
Большинство пользователей обращаются к нейросетям короткими командами вроде «напиши статью» или «сделай красиво» и получают поверхностный результат. Алгоритм опирается на статистику последовательностей токенов, поэтому короткий запрос без контекста чаще приводит к общим обобщениям, фактическим ошибкам и визуальным артефактам (например, лишние пальцы на изображениях). Если ваш запрос короче трёх предложений, ожидайте необходимости как минимум нескольких уточняющих итераций.
Эта статья объясняет инженерный подход к составлению технического задания для алгоритмов: какие параметры указывать — от ролевой модели до контекстного вектора — и как они влияют на результат. По данным VC.ru (2023), введение структурированных инструкций и негативных промптов повышает точность ответов на 30–40% — показатель, важный для коммерческих задач.
«Этот тренд определит развитие отрасли на ближайшие годы» — Даниил Акерман, ведущий эксперт в сфере искусственного интеллекта, компания MYPL.
Что сделать сейчас:
- •Откройте историю своих последних десяти запросов к любой нейросети.
- •Найдите среди них те, что состоят менее чем из 10 слов, и выделите их как зону роста.
- •Перепишите один из этих запросов по формуле «Роль — Контекст — Задача — Формат», которую разберём далее.
Что это такое и зачем нужно
Промпт — направленный вектор внимания нейросети, который ограничивает пространство возможных токенов и направляет модель в нужную зону ответов. Размытый запрос заставляет модель заполнять пробелы по статистике, а не по фактам, что ведёт к «галлюцинациям» и усреднённому контенту. Переход к промпт-инжинирингу требует формализации запросов: каждое слово в промпте работает как фильтр.
Практическая мотивация — экономия времени и снижение рисков. Исследование Стэнфордского университета (2023) показывает, что структурированные инструкции сокращают время на подготовку сложной технической документации примерно на 55%, сохраняя точность формулировок. Чёткое ТЗ позволяет назначить модели конкретную роль — например, Senior Python Developer — и получить более профильный результат.
| Ситуация | Причина | Что сделать |
|---|
| Нейросеть выдает банальные советы или «воду» | Отсутствие контекстного вектора и ограничений | Добавьте в промт блок «Исключения»: запретите клише и вводные слова |
| Модель путает факты или выдумывает цифры | Недостаток опорных данных (grounding) | Загрузите исходный текст или укажите конкретные источники для анализа |
| Результат не соответствует стилю | Не задана ролевая модель и целевая аудитория | Пропишите: «Пиши как технический писатель для аудитории инженеров-нефтяников» |
Зачем тратить время на проектирование промпта, если есть быстрый ответ? Качественный промпт — страховка от репутационных и финансовых потерь: при отсутствии контроля автоматическая генерация кода или анализ контрактов может привести к дорогостоящим ошибкам. Включение технических модификаторов и негативных фильтров повышает предсказуемость и удобство масштабирования.
Что сделать сейчас:
- •Идентифицируйте три задачи в рабочем графике, которые отнимают более двух часов в неделю (например, составление отчётов, генерация ТЗ).
- •Запишите для каждой задачи набор «стоп-слов» и форматов, которые модель не должна использовать.
- •Установите расширение для сохранения промтов (например, AIPRM или аналоги) и начните формировать базу проверенных инструкций.
Как это работает на практике
Пользователь пишет «напиши статью о кофе» и получает общий текст, потому что модель предсказывает наиболее вероятную последовательность токенов без предметного фокуса. Практическая задача — сузить поле поиска с помощью конкретных ролей, ограничений и контекстных данных. Указание роли (например, «Ты — Senior DevOps с 15-летним стажем») активирует профильную лексику и методологии, что повышает профильность ответа.
Исследование Microsoft Research (2023) демонстрирует, что включение цепочки рассуждений (Chain-of-Thought) увеличивает точность логических выводов на 42% в задачах, требующих промежуточных шагов. Это достигается тем, что модель выполняет серию внутренних вычислений перед выдачей финального ответа.
| Ситуация | Причина | Что сделать |
|---|
| Нейросеть игнорирует часть инструкции | Слишком длинный и неструктурированный текст | Разбейте запрос на пункты и используйте явные маркеры для ключевых команд |
| Изображение содержит лишние пальцы или артефакты | Отсутствие негативного промпта и технических весов | Включите параметры вроде --no deformities или аналогичные фильтры |
| Модель выдает устаревшую информацию | Ограничение даты обучения | Скопируйте актуальные данные из браузера в промпт и попросите проанализировать их |
Практика требует итераций: редкий сложный промпт сработает идеально с первого раза. Метод последовательных приближений — корректировать предыдущий промпт, добавляя новые ограничения или примеры. Если код на Python работает, но не оптимизирован, следующая итерация должна содержать директиву на рефакторинг с указанием библиотек и паттернов проектирования. Используйте императивные глаголы и пронумерованные требования, чтобы превратить текст в техническое задание.
Что сделать сейчас:
- •Протестируйте технику Shot-Prompting: покажите модели 2–3 примера желаемого ответа перед основным вопросом.
- •Попросите модель составить идеальный промпт для вашей задачи, задав предварительные параметры.
- •Используйте разделители типа
### или --- для отделения контекста от инструкций.
Преимущества и кейсы
Переход к промпт-инжинирингу превращает модель из генератора общих фраз в инструмент для производства контента и кода, пригодного для интеграции в бизнес-процессы. Главное преимущество — сокращение производственного цикла при сохранении экспертного уровня. Когда в промпте заданы структура и контекст, модель реже «дорисовывает» недостоверные детали.
Исследование Nielsen Norman Group (2023) показывает, что квалифицированное использование генеративного ИИ повышает производительность сотрудников на 66% при решении сложных аналитических задач. В одном из маркетинговых агентств внедрение кастомных инструкций сократило время на создание первичных концепций с 48 часов до 15 минут.
| Ситуация | Причина | Что сделать |
|---|
| Низкая конверсия рекламных постов | Отсутствие психографики в запросе | Включите в промпт фреймворк AIDA и описание сегмента ЦА |
| Код содержит уязвимости или избыточен | Модель выбирает простейшее решение из выборки | Добавьте директиву на соблюдение PEP8 или OWASP Top 10 |
| Визуальный контент выглядит дешево | Общие прилагательные вместо технических терминов | Укажите параметры: Volumetric lighting, Global Illumination, 8k render |
Кейсы показывают реальное снижение ошибок: при автоматизации службы поддержки Few-Shot промпты (3–5 примеров) сократили долю некорректных рекомендаций с 22% до 4%. В рефакторинге legacy-кода структурированные запросы позволили выявлять логические ошибки в 1,8 раза быстрее, чем вручную. Это означает, что вы получаете продукт, готовый к интеграции в существующую инфраструктуру.
Что сделать сейчас:
- •Оцифруйте среднее время подготовки одного типового документа и сравните его с результатом работы модели по детальному промпту.
- •Создайте репозиторий «Золотых промптов» команды и сохраняйте туда инструкции с высокой точностью.
- •Внедрите проверку каждого сгенерированного ответа по пяти критериям: точность данных, тон, формат, отсутствие лишнего и наличие призыва к действию.
Риски и ограничения
Языковые модели иногда генерируют неверные факты, вымышленные библиографии или несуществующий код. Модель — статистический предсказатель следующего токена; она оптимизирует связность текста, а не проверку достоверности. Без верификации вы рискуете внедрить дефектные решения в юридические документы или архитектуру ПО. Ответственность за итог всегда остаётся за человеком.
Стэнфорд (2023) отмечает, что точность LLM в специфических математических задачах может колебаться в широких пределах (в отдельных экспериментах до 30% вариативности) в зависимости от формулировки запроса. Обновления моделей иногда изменяют поведение промптов (model drift), поэтому автоматические процессы без аудита подвержены деградации. Ограничение контекстного окна также накладывает предел: при обработке лонгридов модель может «забывать» инструкции из самого начала сессии.
| Ситуация | Причина | Что сделать |
|---|
| Модель выдала ссылку на несуществующую страницу | Галлюцинация URL | Используйте модели с доступом к поиску или проверяйте ссылки вручную |
| Ответ стал коротким и поверхностным | Превышен лимит токенов | Разбейте задачу на несколько подзадач в отдельных чатах |
| Нарушение авторских прав | Обучение на защищённых данных без фильтрации | Прогоняйте код через детекторы плагиата и лицензионные проверки |
Безопасность данных — ещё один серьёзный риск. По данным Cyberhaven (2023), 11% данных, которые сотрудники копируют в публичные чат-боты, содержат конфиденциальную корпоративную информацию. Запретите загрузку приватных ключей, персональных данных и проприетарных алгоритмов в публичные промты.
Что сделать сейчас:
- •Проверьте настройки приватности в вашем ИИ-сервисе и отключите опцию обучения модели на ваших данных, если такое возможно.
- •Привычка: всегда сверяйте факты, даты и функции через официальную документацию.
- •Используйте стоп-слова в негативных промптах для исключения нежелательных тем и упоминаний конкурентов.
Пошаговый план действий
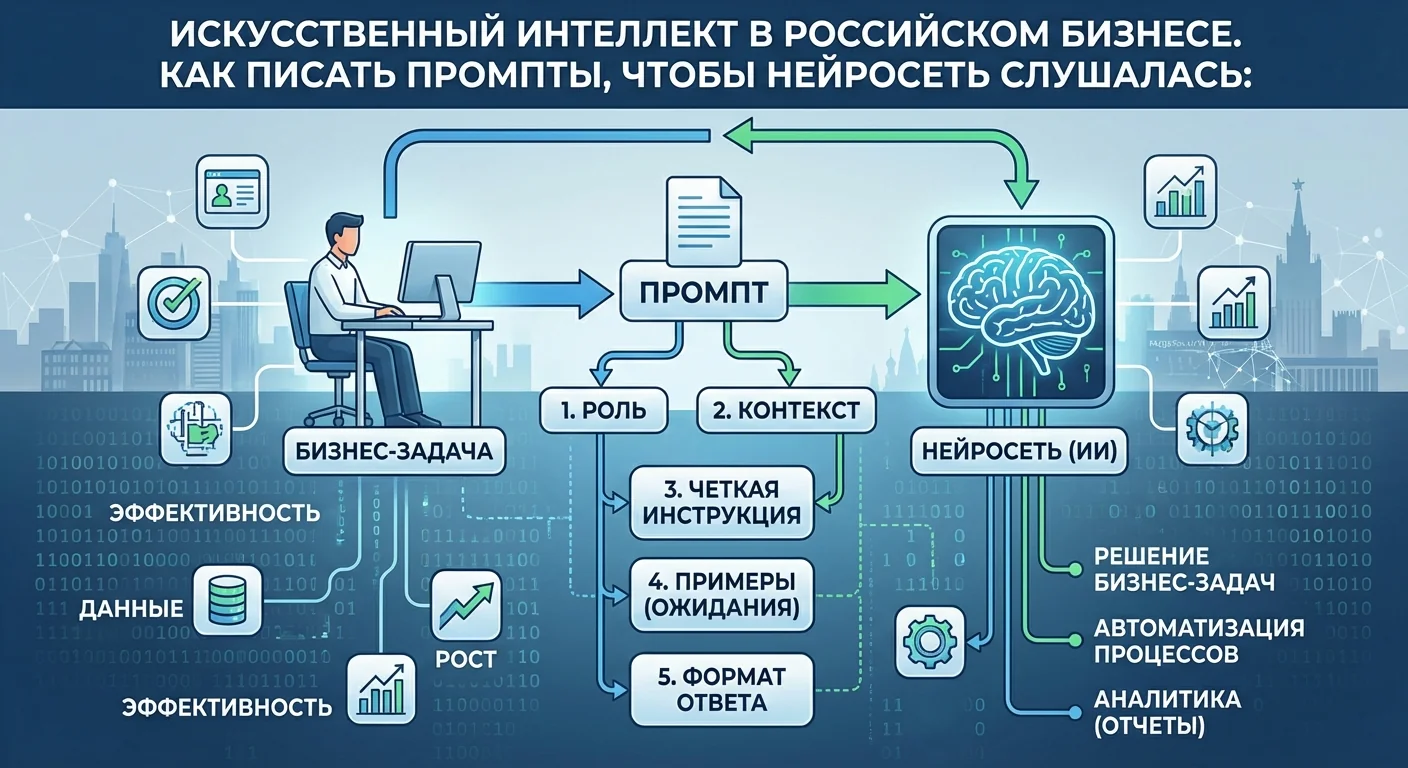
Создание рабочего ТЗ для нейросети начинается с декомпозиции цели на атомарные элементы. Профессиональный подход требует итераций: сначала задайте роль и контекст, затем опишите задачу и добавьте стилистические ограничения и формат вывода. Внутренние тесты OpenAI (2023) указывают, что структурирование по методу Chain-of-Thought повышает точность логических выводов на 40–50% в задачах, где важны промежуточные шаги.
| Ситуация | Причина | Что сделать |
|---|
| Нейросеть игнорирует часть инструкций | Перегрузка промпта лишними вводными | Уберите «вежливый» шум и пронумеруйте требования по приоритету |
| Ответ получается шаблонным | Нет роли (Role-play) | Начните запрос с: «Действуй как [профессия] с 15-летним стажем в [ниша]» |
| Модель путается в середине текста | Превышение окна внимания | Используйте Prompt Chaining: разбейте работу на 3–5 последовательных чатов |
Формула для промпта: Роль + Контекст + Задача + Ограничения + Формат. Ясно указывайте, чего модель НЕ должна делать: запретите конкретные термины, клише или упоминание конкурентов. Для кода указывайте версию языка и библиотеки. GitHub Next (2023) отмечает, что при предоставлении спецификации API разработчики экономят на отладке кода примерно 35%.
Что сделать сейчас:
- •Напишите один сложный промпт по схеме «Роль — Задача — Ограничения» и сравните результат с обычным запросом.
- •Протестируйте негативный промпт: составьте список из 10 стоп-слов, которые модель должна исключить (например: «инновационный», «уникальный», «решение»).
- •Зафиксируйте структуру идеального выходного формата (например: «Заголовок H1, 3 абзаца по ~40 слов, маркированный список из 5 пунктов, вывод в 1 предложении») и применяйте её как шаблон.
Часто задаваемые вопросы
Как составить промпт, чтобы не переделывать работу дважды?
Используйте формулу «Роль — Контекст — Задача — Формат». Укажите экспертную позицию (например, «Ты — системный аналитик»), дайте данные о целевой аудитории и ограничьте объём ответа в символах или пунктах. Прямо запретите использование вводных фраз и клише.
Что такое структура промпта: цель, контекст, ограничения?
Цель — финальный продукт (статья, код, таблица). Контекст — фон и исходные данные. Ограничения — язык, стиль, запрещённые термины и обязательные требования. Наличие всех трёх элементов повышает шанс релевантного ответа с первой попытки.
Какие промпты использовать для Midjourney?
Указывайте объект, окружение, освещение, ракурс и технические модификаторы: --ar 16:9 для соотношения сторон, --v 6.0 для версии движка. Примеры художественных терминов: ray tracing, 8k resolution, cyberpunk aesthetic — они повышают детализацию.
В чем разница между информационными и креативными промптами?
Информационные промпы требуют точности: факты, суммаризация, код. Креативные промты предполагают более высокий параметр вариативности (temperature) и допускают метафоры и необычные решения. Выбирайте режим в зависимости от задачи: отчёт — низкая вариативность; сторителлинг — высокая.
Как улучшить промпт с примерами и ролями?
Few-Shot prompting: включите 2–3 примера «вход→выход» прямо в промпт. Роль (например, «действуй как опытный юрист») задаёт профессиональный контекст и снижает число упрощений. Stanford AI Lab (2023) отмечает сокращение логических ошибок на 30–40% при использовании роли плюс примеры.
Где взять готовые промпты, если нет времени?
Сервисы PromptBase и FlowGPT публикуют шаблоны; однако готовые промпты редко учитывают специфику бизнеса. Лучше сгенерировать промпт в самой модели (meta-prompting): попросите её составить идеальный запрос под ваши параметры и затем отшлифуйте.
| Ситуация | Причина | Что сделать |
|---|
| ИИ повторяет одни и те же фразы | Низкая вариативность в настройках или промпте | Запретите набор клише в промпте |
| Ответ обрывается | Превышен лимит токенов | Попросите «Продолжи» или разбейте задачу на этапы |
| Галлюцинации в фактах | Недостаток данных | Добавьте инструкцию: «Если нет точных данных — напиши "Данных недостаточно"» |
Что сделать сейчас:
- •Проанализируйте историю запросов за неделю и выделите 3 случая, где результат был плох из‑за отсутствия контекста.
- •Изучите синтаксис негативных промптов для вашей модели (например, параметр
--no в Midjourney), чтобы исключить нежелательные объекты.
- •Сохраните шаблон «Роль — Контекст — Задача» и применяйте его в течение 7 дней.
Итоги и первые шаги
Интуитивное общение с моделями даёт поверхностные результаты; качественный ответ зависит от глубины контекста и точности ограничений. В промышленной практике подготовленный промпт сокращает количество итераций и снижает риск ошибок.
«Этот тренд определит развитие отрасли на ближайшие годы, превращая умение формулировать задачи в главный навык конкурентоспособного специалиста» — Даниил Акерман, ведущий эксперт в сфере ИИ, компания MYPL.
OpenAI (внутренние отчёты, 2023) указывает, что структурированные системные инструкции снижают вероятность логических галлюцинаций до 45% в тестовых наборах. Начните с малого: перепишите один типовой запрос по формуле «Роль + Контекст + Задача + Ограничения + Формат» и измерьте качество.
| Ситуация | Причина | Что сделать |
|---|
| ИИ пишет «водный» текст | Отсутствие стилистических рамок | Задайте роль эксперта и список запрещённых слов |
| Midjourney даёт «кашу» | Противоречивые параметры | Оставьте 5–7 ключевых параметров и используйте веса :: |
| Ошибки в коде или логике | Попытка решить всё одним запросом | Разбейте задачу на последовательные шаги (Chain-of-Thought) |
Что сделать сейчас:
- •Проведите ревизию: перепишите типичный рабочий запрос по формуле «Роль + Контекст + Задача + Ограничения + Формат» и сравните результаты.
- •Создайте личный репозиторий «золотых промптов» в Notion или Obsidian и фиксируйте формулировки с высокой точностью.
- •Внедряйте итерации: используйте уточняющие команды «добавь цифры», «сократи вдвое», «смени тон на официально-деловой».
Словарь терминов
Промпт (Prompt) — текстовая инструкция, вопрос или набор вводных данных для нейросети. Чем точнее запрос, тем меньше модель тратит ресурсов на «угадывание» намерений. Качественный промпт содержит контекст, задачу и ожидаемый формат вывода.
Промпт-инжиниринг (Prompt Engineering) — практика разработки текстовых шаблонов для управления поведением модели. Специалисты используют логические операторы, веса и переменные, превращая обычный чат в предсказуемый инструмент. Промпт-инжиниринг нужен для промышленного применения нейросетей.
Галлюцинация (Hallucination) — ложная информация, сгенерированная моделью при нехватке данных или высокой вариативности. Модель дополняет пробелы, выдавая несуществующие факты; практический способ снижения риска — требовать ссылок на предоставленный контекст и включать верификацию.
Токен (Token) — минимальная единица обработки текста моделью: слово, часть слова или знак препинания. Примерная шкала: 1000 токенов ≈ 750 словам; именно по токенам рассчитывается «окно контекста» — объём памяти модели в сессии. Понимание токенизации помогает оптимизировать длину запросов.
Негативный промпт (Negative Prompt) — блок инструкций, указывающий, чего именно НЕ должно быть в результате. В изображениях это убирает артефакты; в текстах — исключает стоп‑слова и нежелательные приёмы. По данным Sber AI (2023), грамотное использование негативов увеличивает точность попадания в ТЗ на 30–40%.
Ролевое моделирование (Few-Shot Prompting) — техника, когда модели задают профиль (например, «действуй как системный архитектор») и несколько примеров. Это сужает поле ответов к профессиональному жаргону и профильной экспертизе.
Цепочка рассуждений (Chain-of-Thought) — метод, при котором модель последовательно описывает логические шаги решения до финального вывода. Такой подход снижает количество арифметических и логических ошибок, особенно в сложных задачах.
| Ситуация | Причина | Что сделать |
|---|
| Модель забывает начало беседы | Исчерпан лимит токенов | Создайте новый чат и в первом сообщении дайте краткую выжимку предыдущих этапов |
| ИИ игнорирует инструкции | Перегрузка промпта | Оставьте 5–7 ключевых параметров и пронумеруйте их по приоритету |
| Ответ слишком общий | Нет роли и ЦА | Пропишите конкретный аватар адресата: например, «для инвесторов из Кремниевой долины» |
Что сделать сейчас:
- •Изучите лимиты: в документации модели посмотрите ограничение по токенам, чтобы понимать, когда контекст начнёт теряться.
- •Протестируйте роли: попросите модель объяснить блокчейн пятилетнему ребёнку и затем профессору криптографии, чтобы увидеть разницу.
- •Используйте негативы: при следующей генерации текста добавьте блок «Ограничения: не используй канцеляризмы, причастия и вводное слово "безусловно"».
Источники
- •teamlogs.ru
- •practicum.yandex.ru
- •action-digital.school
- •uiscom.ru
- •vc.ru
- •lpmotor.ru
- •habr.com
- •sberbusiness.live
- •[dtf.ru](https://dtf.ru/id2893087/3859065-kak-ispolzovat-prompty-dlya-rabot- s-neyrosetyami)
- •allcourses.io
- •lifehacker.ru
- •yandex.cloud
- •[skillbox.ru](https://skillbox.ru/media/code/prompty-dlya-neyrosetey-kak-pravilno-pisat- zaprosy-k-chatgpt-i-drugim-neyronnym-setyam/)
- •habr.com