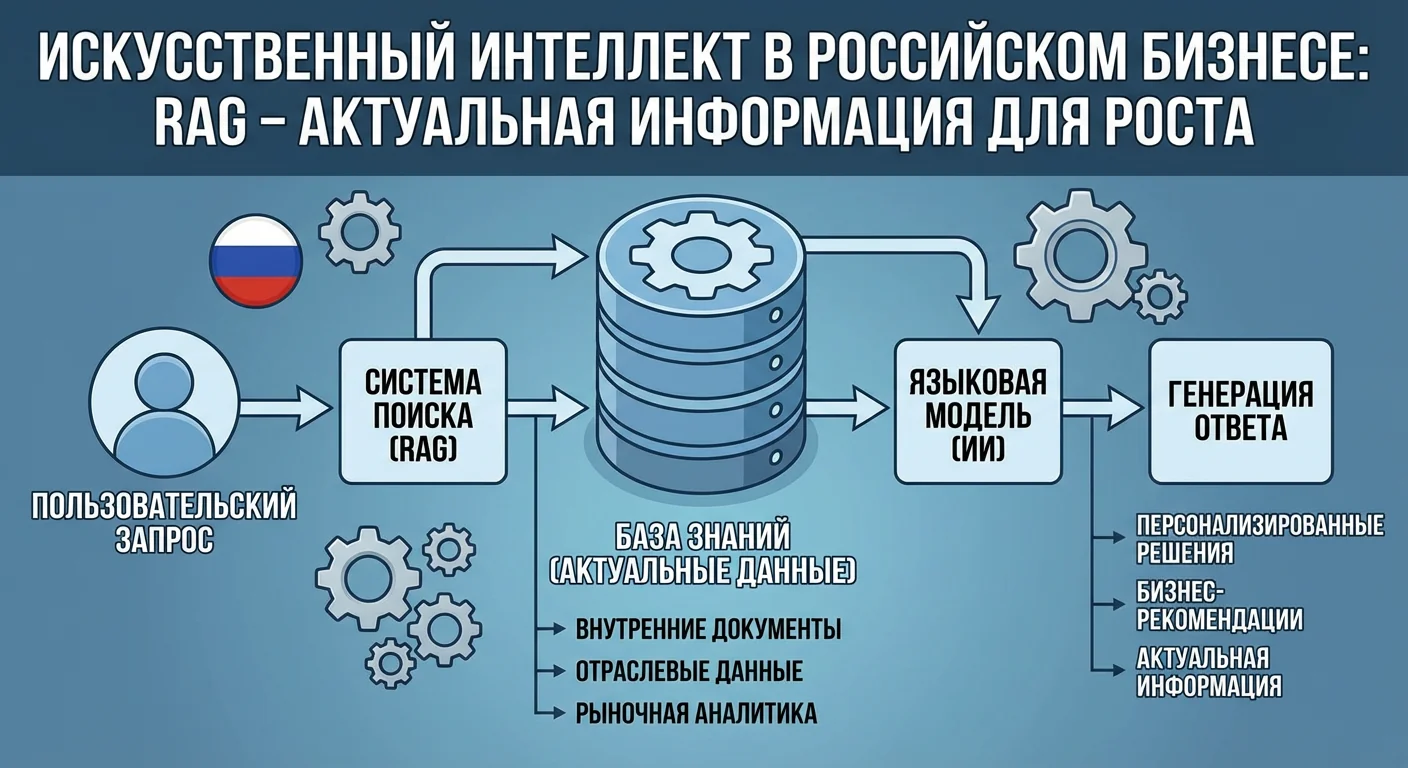
RAG (Retrieval-Augmented Generation) для актуальной информации
Языковые модели обучены на данных до определенной даты, что означает, что они не знают о событиях, произошедших после обучения, и не имеют доступа к специфической информации, которой нет в их обучающих данных. Это создает проблему для приложений, требующих актуальной информации или работы с корпоративными данными. RAG (Retrieval-Augmented Generation) решает эту проблему, объединяя возможности языковых моделей с системами поиска информации.
RAG работает по принципу двухэтапного процесса: сначала система извлекает релевантную информацию из внешних источников (базы данных, документы, веб-страницы), затем языковая модель использует эту информацию для генерации ответа. Это позволяет моделям работать с актуальными данными, специфической информацией и большими объемами документов, которые не могли быть включены в обучающий набор.
В 2025 году RAG стал стандартным подходом для создания AI-приложений, работающих с актуальной информацией и корпоративными данными. От чат-ботов с доступом к базе знаний до систем анализа документов — RAG находит применение в самых разных областях. Как работает RAG? Какие архитектуры используются? Как реализовать RAG-систему? Разберём принципы работы RAG, различные подходы к реализации, практические применения и рекомендации по использованию.
Принципы работы RAG
RAG основан на простой, но мощной идее: вместо того чтобы полагаться только на знания модели, система сначала находит релевантную информацию, а затем использует ее для генерации ответа. Понимание этого принципа — ключ к пониманию RAG.
Первый этап — индексация документов. Перед использованием RAG-системы документы должны быть обработаны и проиндексированы. Это включает разбиение документов на фрагменты (chunks), создание векторных представлений (embeddings) для каждого фрагмента и сохранение их в векторной базе данных. Индексация позволяет системе быстро находить релевантные фрагменты для запросов пользователей.
Второй этап — поиск релевантной информации. Когда пользователь задает вопрос, система создает векторное представление запроса и ищет наиболее похожие фрагменты в векторной базе данных. Поиск основан на семантическом сходстве, а не на точном совпадении слов, что позволяет находить релевантную информацию даже при использовании разных формулировок.
Третий этап — контекстуализация. Найденные фрагменты объединяются с исходным запросом пользователя в промпт для языковой модели. Модель получает контекст из найденных документов и использует его для генерации ответа. Это позволяет модели генерировать ответы на основе актуальной и специфической информации, которой нет в ее обучающих данных.
Четвертый этап — генерация ответа. Языковая модель генерирует ответ, используя информацию из найденных документов. Модель может цитировать источники, синтезировать информацию из нескольких документов, отвечать на вопросы, требующие актуальных данных. Качество ответа зависит как от качества поиска, так и от способности модели использовать найденную информацию.
Архитектуры RAG
Существует несколько архитектурных подходов к реализации RAG. Каждый подход имеет свои преимущества и оптимальные сценарии использования.
Базовая RAG архитектура — простейший подход, при котором запрос пользователя используется для поиска релевантных документов, которые затем передаются модели вместе с запросом. Модель генерирует ответ на основе найденных документов. Этот подход прост в реализации, но может иметь ограничения в качестве, особенно для сложных запросов.
Многоэтапная RAG — расширение базовой архитектуры, при котором поиск выполняется в несколько этапов. Сначала выполняется широкий поиск для понимания контекста, затем более специфический поиск для получения детальной информации. Многоэтапный подход может улучшить качество для сложных запросов, требующих информации из разных источников или уровней детализации.
Гибридный поиск — комбинация семантического поиска (по векторным представлениям) и ключевого поиска (по точным совпадениям). Гибридный подход использует преимущества обоих методов: семантический поиск находит релевантную информацию по смыслу, ключевой поиск находит точные совпадения терминов. Комбинация может улучшить качество поиска, особенно для запросов с конкретными терминами.
Reranking — добавление этапа переранжирования результатов поиска перед передачей модели. После первоначального поиска результаты переранжируются с помощью более точной модели, которая лучше оценивает релевантность. Reranking может значительно улучшить качество, отфильтровывая менее релевантные результаты и улучшая порядок найденных документов.
Адаптивная RAG — подход, при котором система адаптивно выбирает, использовать ли RAG или полагаться только на знания модели. Для простых вопросов, на которые модель может ответить из своих знаний, RAG может не использоваться, что снижает задержку и стоимость. Для сложных или специфических вопросов используется RAG. Адаптивный подход оптимизирует баланс между качеством и эффективностью.
Компоненты RAG-системы
RAG-система состоит из нескольких ключевых компонентов, каждый из которых играет важную роль. Понимание этих компонентов помогает правильно спроектировать систему.
Компонент индексации — обрабатывает документы и создает индекс для поиска. Этот компонент разбивает документы на фрагменты, создает векторные представления, сохраняет метаданные и индексирует все это в векторной базе данных. Качество индексации критически важно для качества всей системы.
Векторная база данных — хранит векторные представления документов и обеспечивает быстрый поиск похожих векторов. Выбор векторной базы данных влияет на скорость поиска, масштабируемость и возможности системы. Популярные варианты включают Pinecone, Weaviate, Qdrant, Milvus, Chroma.
Модель эмбеддингов — преобразует текст в векторные представления. Качество модели эмбеддингов определяет качество семантического поиска. Различные модели оптимизированы для разных задач: некоторые лучше работают с короткими текстами, другие — с длинными документами, некоторые специализированы на определенных языках или доменах.
Языковая модель — генерирует финальный ответ на основе найденных документов и запроса пользователя. Выбор модели влияет на качество генерации, способность синтезировать информацию из нескольких источников, форматирование ответов. Различные модели могут иметь разные сильные стороны для задач RAG.
Компонент постобработки — обрабатывает результаты перед возвратом пользователю. Это может включать форматирование, добавление ссылок на источники, проверку качества ответа, фильтрацию нежелательного контента. Постобработка помогает обеспечить качество и полезность финального ответа.
Оптимизация качества RAG
Качество RAG-системы зависит от многих факторов. Рассмотрим основные аспекты оптимизации.
Качество индексации — критически важно для качества всей системы. Правильное разбиение документов на фрагменты, выбор размера фрагментов, обработка границ фрагментов — все это влияет на качество поиска. Фрагменты должны быть достаточно большими, чтобы содержать полную информацию, но достаточно маленькими, чтобы быть релевантными для конкретных запросов.
Качество поиска — зависит от модели эмбеддингов, векторной базы данных и стратегии поиска. Выбор подходящей модели эмбеддингов для вашей задачи, настройка параметров поиска, использование гибридного поиска или reranking могут значительно улучшить качество. Тестирование различных подходов помогает найти оптимальную конфигурацию.
Качество промпта — промпт, передаваемый языковой модели, должен четко указывать, как использовать найденные документы. Инструкции по использованию контекста, форматированию ответа, цитированию источников влияют на качество генерации. Хорошо структурированный промпт может значительно улучшить результаты.
Обработка контекста — способность модели эффективно использовать информацию из найденных документов. Модель должна уметь синтезировать информацию из нескольких источников, определять релевантность информации, игнорировать нерелеванные части контекста. Выбор модели и настройка промпта влияют на эту способность.
Мониторинг и улучшение — постоянный мониторинг качества системы и улучшение на основе обратной связи. Анализ случаев, когда система дает неудовлетворительные результаты, помогает выявить проблемы и улучшить систему. Итеративное улучшение — ключ к поддержанию высокого качества.
Практические применения
RAG находит применение в самых разных областях. Рассмотрим основные области применения.
Корпоративные чат-боты — одно из самых распространенных применений RAG. Чат-боты с доступом к корпоративной базе знаний могут отвечать на вопросы сотрудников, используя актуальную информацию из документов компании. Это особенно полезно для больших организаций с большим объемом документации.
Системы анализа документов — использование RAG для анализа больших объемов документов и извлечения информации. Системы могут отвечать на вопросы о документах, находить релевантную информацию, синтезировать информацию из нескольких источников. Это полезно для юридических фирм, исследовательских организаций, компаний с большим объемом документации.
Образовательные приложения — использование RAG для создания обучающих систем с доступом к актуальным материалам. Системы могут отвечать на вопросы студентов, используя актуальные учебные материалы, научные статьи, образовательный контент. Это позволяет создавать более актуальные и полезные обучающие системы.
Системы поддержки клиентов — использование RAG для создания систем поддержки с доступом к актуальной информации о продуктах, услугах, политиках компании. Системы могут отвечать на вопросы клиентов, используя актуальную информацию, что улучшает качество поддержки и снижает нагрузку на сотрудников.
Исследовательские инструменты — использование RAG для создания инструментов исследования с доступом к актуальным научным статьям, новостям, данным. Исследователи могут задавать вопросы и получать ответы на основе актуальной информации из различных источников.
Вызовы и ограничения
RAG имеет ряд вызовов и ограничений, которые важно учитывать. Понимание этих ограничений помогает правильно планировать и реализовывать RAG-системы.
Вызов актуальности данных — необходимость обновления индекса при изменении документов. Если документы обновляются, индекс должен быть обновлен, чтобы система работала с актуальными данными. Это требует инфраструктуры для отслеживания изменений и обновления индекса.
Вызов качества поиска — поиск может находить нерелевантные документы или пропускать релевантные. Качество поиска зависит от многих факторов: качества модели эмбеддингов, способа разбиения документов, стратегии поиска. Улучшение качества поиска требует экспериментов и настройки.
Вызов обработки контекста — модели могут неправильно использовать найденную информацию или смешивать информацию из разных источников. Модели могут генерировать ответы, которые не полностью основаны на найденных документах, или неправильно интерпретировать информацию. Это требует тщательной настройки промптов и мониторинга качества.
Вызов масштабируемости — RAG-системы могут быть дорогими в масштабировании из-за необходимости хранить и индексировать большие объемы данных. Векторные базы данных и модели эмбеддингов требуют вычислительных ресурсов, что может создавать проблемы при масштабировании. Выбор правильной инфраструктуры критически важен.
Вызов задержки — RAG-системы могут иметь большую задержку из-за необходимости выполнения поиска перед генерацией. Поиск в векторной базе данных и генерация ответа добавляют задержку по сравнению с простой генерацией. Оптимизация задержки требует балансирования между качеством и скоростью.
Рекомендации по реализации
При реализации RAG-системы стоит следовать нескольким рекомендациям. Начните с простой архитектуры и постепенно усложняйте. Базовая RAG архитектура может дать хорошие результаты для многих задач, и усложнение не всегда улучшает качество. Добавляйте сложность только когда это действительно необходимо.
Тестируйте на репрезентативных данных. Качество RAG сильно зависит от данных, поэтому важно тестировать на данных, похожих на production данные. Тестирование на различных типах запросов и документов помогает выявить проблемы и улучшить систему.
Мониторьте качество и собирайте обратную связь. Постоянный мониторинг качества системы помогает выявить проблемы и улучшить систему. Сбор обратной связи от пользователей помогает понять, где система работает хорошо, а где нужны улучшения.
Используйте правильные инструменты. Выбор подходящих инструментов для вашей задачи может значительно упростить реализацию и улучшить качество. Существует множество библиотек и платформ, которые упрощают создание RAG-систем.
Оптимизируйте для вашей задачи. Различные задачи могут требовать различных подходов к RAG. Адаптация архитектуры, выбора моделей, стратегии поиска под конкретную задачу может значительно улучшить результаты.
Будущее RAG
RAG продолжает развиваться, и можно ожидать дальнейших улучшений. Рассмотрим перспективы развития.
Ожидается улучшение качества поиска за счет разработки более эффективных моделей эмбеддингов и стратегий поиска. Новые модели и подходы могут улучшить способность систем находить релевантную информацию, особенно для сложных или нестандартных запросов.
Вероятно развитие более интеллектуальных стратегий поиска. Системы могут научиться адаптивно выбирать стратегию поиска в зависимости от типа запроса, использовать многоэтапный поиск более эффективно, лучше обрабатывать сложные запросы, требующие информации из разных источников.
Ожидается улучшение интеграции с языковыми моделями. Более тесная интеграция между компонентами поиска и генерации может улучшить способность моделей использовать найденную информацию. Это может включать улучшенные промпты, лучшую обработку контекста, более эффективное синтезирование информации.
Вероятно развитие специализированных RAG-систем для конкретных доменов. Создание систем, оптимизированных для конкретных областей (медицина, право, финансы), может улучшить качество и эффективность в этих областях.
Заключение
RAG представляет собой мощный подход к созданию AI-приложений, работающих с актуальной информацией и специфическими данными. Объединение возможностей языковых моделей с системами поиска информации открывает новые возможности для создания интеллектуальных систем.
Понимание принципов работы RAG, различных архитектурных подходов и компонентов системы важно для правильной реализации. Выбор подходящей архитектуры, инструментов и стратегии оптимизации зависит от конкретных требований задачи.
Для практического применения важно понимать принципы RAG, уметь выбирать подходящие инструменты и подходы, тестировать и оптимизировать систему. Итеративный процесс улучшения и внимание к качеству — ключ к созданию эффективных RAG-систем.
Словарь терминов
RAG (Retrieval-Augmented Generation) — подход к генерации текста, при котором система сначала извлекает релевантную информацию из внешних источников, затем использует ее для генерации ответа.
Индексация — процесс обработки документов и создания структурированного индекса для быстрого поиска релевантной информации.
Фрагмент (Chunk) — часть документа, на которую разбивается документ для индексации и поиска в RAG-системах.
Эмбеддинг (Embedding) — векторное представление текста, создаваемое моделью для семантического поиска.
Векторная база данных — специализированная база данных для хранения и поиска векторных представлений по семантическому сходству.
Семантический поиск — поиск информации на основе смыслового сходства, а не точного совпадения слов.
Гибридный поиск — комбинация семантического поиска и ключевого поиска для улучшения качества результатов.
Reranking — процесс переранжирования результатов поиска с помощью более точной модели для улучшения порядка результатов.
Адаптивная RAG — подход, при котором система адаптивно выбирает, использовать ли RAG или полагаться только на знания модели.
Контекстуализация — процесс объединения найденных документов с запросом пользователя для создания контекста для языковой модели.