Vision Transformers: революция в компьютерном зрении
Традиционные подходы к компьютерному зрению десятилетиями полагались на сверточные нейронные сети (CNN). Архитектуры вроде ResNet, VGG или EfficientNet стали стандартом для задач распознавания изображений, детекции объектов и сегментации. Однако в 2020 году появилась альтернатива, которая кардинально изменила подход к обработке изображений — Vision Transformers (ViT). Эта архитектура адаптировала успешный механизм внимания из языковых моделей для работы с изображениями, открыв новые возможности в компьютерном зрении.
Vision Transformers представляют собой фундаментальный сдвиг парадигмы: вместо использования сверточных операций для извлечения локальных признаков, ViT разбивает изображение на патчи и обрабатывает их как последовательность, применяя механизм самовнимания для моделирования глобальных зависимостей. Этот подход оказался невероятно эффективным: современные ViT модели превосходят лучшие CNN на многих задачах, особенно когда доступны большие объемы данных для обучения.
В 2025 году Vision Transformers стали доминирующей архитектурой во многих областях компьютерного зрения. От базовой классификации изображений до сложных задач вроде генерации изображений или видеоанализа — ViT находят применение везде. Как работает эта архитектура? Почему она оказалась настолько эффективной? Какие практические применения она открывает? Пройдёмся по шагам принципы работы Vision Transformers, их архитектурные особенности, сравнение с CNN и практические рекомендации по использованию.
Принцип работы Vision Transformers
Vision Transformers работают по принципу, кардинально отличающемуся от традиционных CNN. Понимание этого принципа — ключ к пониманию силы ViT.
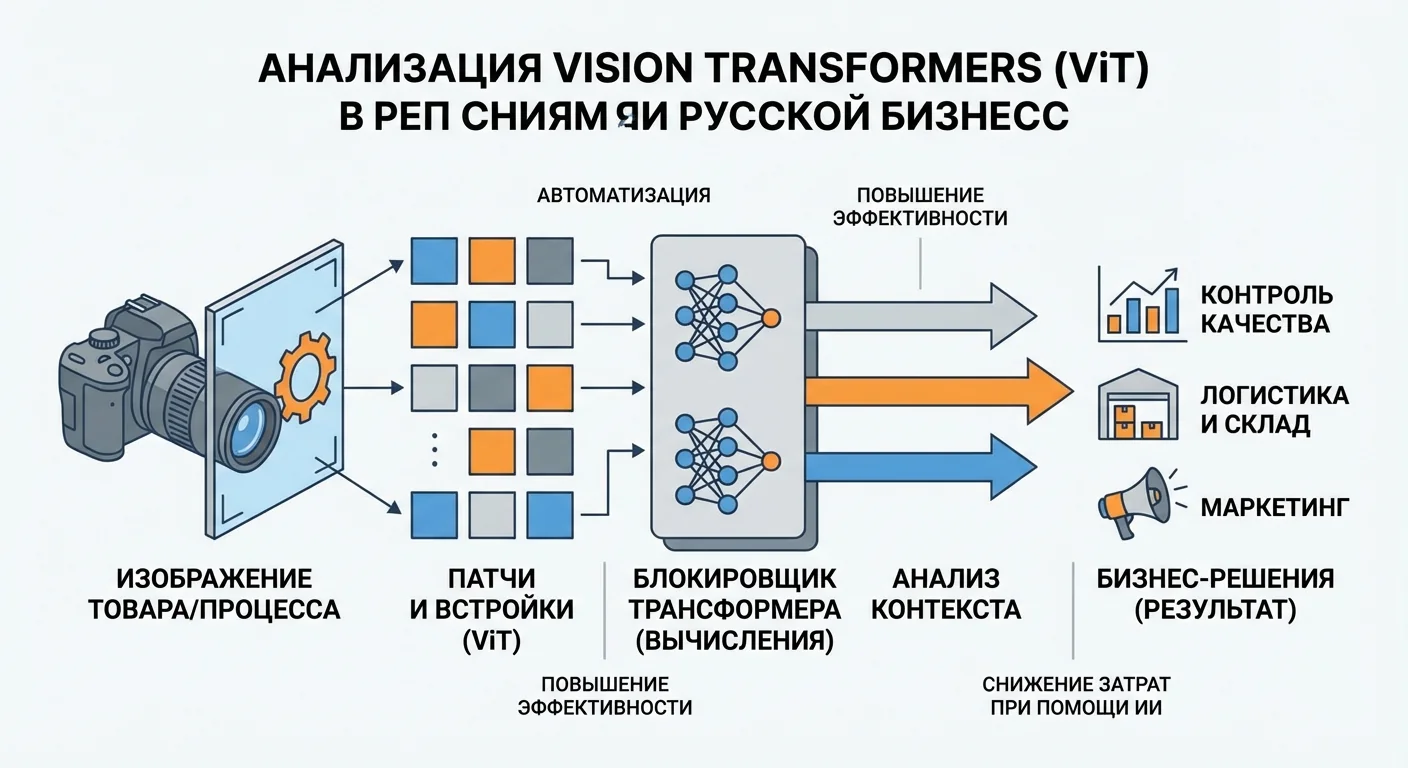
Первый шаг — разбиение изображения на патчи. Входное изображение делится на небольшие квадратные патчи (обычно 16x16 или 32x32 пикселя). Каждый патч рассматривается как отдельный "токен", аналогично тому, как слова разбиваются на токены в языковых моделях. Это преобразование изображения в последовательность патчей является фундаментальным отличием ViT от CNN, которые работают с пикселями напрямую через сверточные фильтры.
Второй шаг — линейное проецирование патчей. Каждый патч преобразуется в вектор фиксированной размерности через линейный слой. Это создает последовательность векторов, которая может обрабатываться трансформерной архитектурой. Размерность этих векторов определяет "скрытую размерность" модели и влияет на ее способность к обучению.
Третий шаг — добавление позиционных энкодингов. В отличие от CNN, которые автоматически учитывают пространственные отношения через сверточные операции, ViT должны явно обучаться понимать позиции патчей. Для этого к каждому патчу добавляется позиционное энкодирование, которое сообщает модели о расположении патча в исходном изображении. Это критически важно для правильной работы модели.
Четвертый шаг — обработка через трансформерные блоки. Последовательность патчей проходит через серию трансформерных блоков, каждый из которых содержит механизм самовнимания и feed-forward сети. Механизм внимания позволяет каждому патчу "видеть" и взаимодействовать со всеми другими патчами, что дает модели возможность моделировать глобальные зависимости в изображении. Это ключевое преимущество ViT: они могут учитывать связи между удаленными частями изображения с самого начала, в то время как CNN должны постепенно расширять рецептивное поле через множество слоев.
Пятый шаг — классификация или другая задача. После обработки через трансформерные блоки, специальный токен [CLS] или усреднение всех патчей используется для получения финального представления изображения, которое затем используется для решения конкретной задачи: классификации, детекции объектов, сегментации и т.д.
Архитектурные компоненты ViT
Vision Transformers состоят из нескольких ключевых компонентов, каждый из которых играет важную роль. Понимание этих компонентов помогает понять, как работает ViT и как его можно оптимизировать.
Патч эмбеддинг (Patch Embedding) — первый компонент, который преобразует изображение в последовательность векторов. Этот компонент включает разбиение изображения на патчи и линейное проецирование каждого патча в векторное пространство. Качество патч эмбеддинга влияет на способность модели извлекать полезные признаки из изображения. Некоторые современные варианты ViT используют более сложные методы эмбеддинга, включая сверточные слои для предобработки патчей.
Позиционное энкодирование (Positional Encoding) — критически важный компонент, который добавляет информацию о пространственном расположении патчей. Без позиционного энкодирования модель не сможет понять, что патч в верхнем левом углу находится рядом с патчем справа от него, а не с патчем в нижнем правом углу. Существуют различные подходы к позиционному энкодированию: фиксированные синусоидальные энкодирования, обучаемые энкодирования, или относительные позиционные энкодирования. Выбор подхода может влиять на качество модели и ее способность обобщаться на изображения разных размеров.
Трансформерные блоки (Transformer Blocks) — сердце ViT архитектуры. Каждый блок содержит механизм самовнимания (self-attention) и feed-forward сеть с остаточными соединениями и нормализацией слоев. Механизм самовнимания позволяет модели вычислять веса внимания между всеми парами патчей, определяя, какие патчи важны для понимания каждого конкретного патча. Multi-head attention расширяет это, позволяя модели фокусироваться на разных аспектах одновременно.
Механизм внимания в ViT работает следующим образом: для каждого патча вычисляются запрос (query), ключ (key) и значение (value) векторы. Затем вычисляются веса внимания как скалярное произведение запросов и ключей, которые определяют, насколько каждый патч должен влиять на другие патчи. Эти веса используются для взвешенного суммирования значений, создавая обновленное представление каждого патча, которое учитывает информацию из всех других патчей.
Классификационный токен (CLS Token) — специальный токен, добавляемый в начало последовательности патчей. Этот токен собирает информацию из всех патчей через механизм внимания и используется для финальной классификации изображения. Альтернативный подход — использование усреднения всех патчей или пулинга, но CLS токен часто показывает лучшие результаты, так как специально обучается для агрегации информации.
Преимущества Vision Transformers
Vision Transformers предлагают несколько ключевых преимуществ по сравнению с традиционными CNN. Понимание этих преимуществ помогает оценить, когда стоит использовать ViT.
Первое преимущество — глобальное восприятие с самого начала. CNN должны постепенно расширять рецептивное поле через множество слоев, что требует глубоких сетей для учета глобального контекста. ViT могут моделировать глобальные зависимости сразу благодаря механизму внимания, который позволяет каждому патчу взаимодействовать со всеми другими патчами. Это особенно полезно для задач, где важны глобальные паттерны или долгосрочные зависимости.
Второе преимущество — масштабируемость. ViT демонстрируют лучшую масштабируемость при увеличении размера модели и объема обучающих данных. Исследования показывают, что ViT продолжают улучшаться при увеличении размера, в то время как CNN могут достигать плато. Это делает ViT особенно привлекательными для задач, где доступны большие объемы данных и вычислительные ресурсы.
Третье преимущество — универсальность архитектуры. Одна и та же трансформерная архитектура может использоваться для различных задач: классификации, детекции объектов, сегментации, генерации. Это упрощает разработку и позволяет переносить знания между задачами. Более того, предобученные ViT модели могут быть эффективно адаптированы для различных задач через fine-tuning или transfer learning.
Четвертое преимущество — интерпретируемость. Механизм внимания в ViT позволяет визуализировать, на какие части изображения модель обращает внимание при принятии решений. Это делает ViT более интерпретируемыми, чем CNN, где понять, что именно влияет на решение, может быть сложнее. Визуализация внимания помогает отлаживать модели и понимать их поведение.
Пятое преимущество — эффективность на больших данных. ViT особенно эффективны, когда доступны большие объемы обучающих данных. На малых датасетах ViT могут уступать CNN, но при достаточном количестве данных ViT часто превосходят CNN. Это делает ViT идеальным выбором для задач, где можно собрать или использовать большие датасеты.
Ограничения и вызовы
Несмотря на преимущества, Vision Transformers имеют ряд ограничений, которые важно учитывать при выборе архитектуры.
Первое ограничение — требования к данным. ViT требуют больших объемов обучающих данных для достижения хороших результатов. На малых датасетах ViT могут уступать CNN, которые лучше обобщаются при ограниченных данных. Это связано с тем, что ViT имеют больше параметров и более гибкую архитектуру, что требует больше данных для обучения. Для решения этой проблемы используются различные техники: data augmentation, transfer learning, или гибридные подходы, комбинирующие CNN и ViT.
Второе ограничение — вычислительная сложность. Механизм самовнимания имеет квадратичную сложность относительно количества патчей. Для изображения высокого разрешения количество патчей может быть очень большим, что делает вычисления дорогими. Для решения этой проблемы разработаны различные оптимизации: sparse attention, linear attention, или иерархические подходы, которые обрабатывают изображения на разных уровнях разрешения.
Третье ограничение — отсутствие индуктивных предпосылок. CNN имеют встроенные индуктивные предпосылки о пространственной локальности и трансляционной инвариантности благодаря сверточным операциям. ViT должны обучаться этим предпосылкам с нуля, что может требовать больше данных и времени обучения. Некоторые современные варианты ViT пытаются включить эти предпосылки через гибридные архитектуры или специальные техники энкодирования.
Четвертое ограничение — сложность работы с изображениями разных размеров. CNN легко обрабатывают изображения разных размеров благодаря сверточным операциям, которые инвариантны к размеру. ViT требуют фиксированного количества патчей, что делает работу с изображениями разных размеров более сложной. Для решения этой проблемы используются различные техники: интерполяция позиционных энкодирований, адаптивные патчи, или иерархические подходы.
Пятое ограничение — интерпретация позиций. Хотя позиционное энкодирование позволяет ViT понимать пространственные отношения, это понимание может быть менее точным, чем встроенное понимание в CNN. Это может влиять на задачи, где важны точные пространственные отношения.
Сравнение с CNN
Понимание различий между ViT и CNN помогает принимать обоснованные решения о выборе архитектуры. Рассмотрим ключевые различия.
CNN используют сверточные операции для извлечения локальных признаков и постепенно расширяют рецептивное поле через множество слоев. Это делает CNN эффективными для задач, где важны локальные паттерны, и они хорошо работают даже на малых датасетах благодаря индуктивным предпосылкам. CNN также более эффективны в вычислениях для изображений высокого разрешения.
ViT используют механизм внимания для моделирования глобальных зависимостей с самого начала. Это делает ViT особенно эффективными для задач, где важны глобальные паттерны или долгосрочные зависимости. ViT лучше масштабируются при увеличении размера модели и данных, но требуют больше данных для обучения.
Выбор между ViT и CNN зависит от конкретных требований задачи: размера датасета, доступных вычислительных ресурсов, типа задачи. Для многих задач гибридные подходы, комбинирующие CNN и ViT, могут быть оптимальными, используя преимущества обеих архитектур.
Современные варианты ViT
С момента появления оригинального ViT было разработано множество вариантов, улучшающих различные аспекты архитектуры. Рассмотрим наиболее важные варианты.
DeiT (Data-efficient Image Transformers) — вариант ViT, оптимизированный для работы с ограниченными данными. DeiT использует дистилляцию знаний от большой CNN модели и специальные техники обучения для достижения хороших результатов на меньших датасетах. Это делает DeiT более практичным для задач, где большие датасеты недоступны.
Swin Transformer — иерархический вариант ViT, который обрабатывает изображения на разных уровнях разрешения. Swin Transformer использует shifted windows для эффективного моделирования локальных и глобальных зависимостей, что делает его более эффективным в вычислениях и лучше работающим на различных задачах. Swin Transformer стал популярным выбором для многих задач компьютерного зрения.
PVT (Pyramid Vision Transformer) — еще один иерархический подход, который создает пирамидальную структуру признаков, аналогичную CNN. PVT обрабатывает изображения на разных уровнях разрешения, что делает его эффективным для задач детекции объектов и сегментации, где важна многоуровневая информация.
ViT-G/14 и другие большие модели — варианты ViT с огромным количеством параметров (миллиарды), которые демонстрируют исключительное качество на различных задачах. Эти модели требуют значительных вычислительных ресурсов для обучения и использования, но показывают state-of-the-art результаты на многих бенчмарках.
DINO и другие self-supervised подходы — варианты ViT, обучаемые без размеченных данных через self-supervised learning. Эти подходы позволяют обучать ViT на больших объемах неразмеченных данных, что особенно полезно для задач, где размеченные данные ограничены.
Практические применения
Vision Transformers находят применение в различных областях компьютерного зрения. Рассмотрим основные области применения.
Классификация изображений — базовая задача, где ViT показывают отличные результаты. Современные ViT модели превосходят лучшие CNN на многих бенчмарках классификации изображений, особенно при наличии больших объемов данных. ViT используются в приложениях для распознавания объектов, анализа медицинских изображений, контроля качества в производстве.
Детекция объектов — задача, где ViT показывают сильные результаты благодаря способности моделировать глобальные зависимости. Иерархические варианты ViT вроде Swin Transformer особенно эффективны для детекции объектов, так как могут обрабатывать изображения на разных уровнях разрешения и учитывать контекст на разных масштабах.
Сегментация изображений — еще одна область, где ViT эффективны. Способность моделировать глобальные зависимости помогает ViT лучше понимать границы объектов и контекст сцены. ViT используются для семантической и instance сегментации в различных приложениях: автономное вождение, медицинская визуализация, анализ спутниковых снимков.
Генерация изображений — область, где ViT находят применение через архитектуры вроде DALL-E или других генеративных моделей. ViT могут использоваться как часть генеративных моделей для создания изображений на основе текстовых описаний или других входных данных.
Видеоанализ — перспективное направление для ViT. Обработка видео как последовательности изображений позволяет применять ViT для задач анализа видео: распознавание действий, трекинг объектов, анализ поведения. Временное измерение добавляет дополнительную сложность, но ViT могут эффективно моделировать временные зависимости через механизм внимания.
Рекомендации по использованию
При выборе и использовании Vision Transformers стоит учитывать несколько рекомендаций. Определите размер вашего датасета: для больших датасетов ViT могут быть оптимальным выбором, для малых датасетов рассмотрите варианты вроде DeiT или гибридные подходы.
Используйте transfer learning. Предобученные ViT модели на больших датасетах могут быть эффективно адаптированы для ваших задач через fine-tuning. Это особенно важно для задач с ограниченными данными, где обучение с нуля может быть неэффективным.
Рассмотрите гибридные подходы. Комбинирование CNN и ViT может дать лучшее из обоих миров: эффективность CNN для локальных признаков и способность ViT моделировать глобальные зависимости. Многие современные архитектуры используют гибридный подход.
Оптимизируйте для вашей задачи. Различные варианты ViT оптимизированы для разных задач: Swin Transformer для детекции объектов, DeiT для малых датасетов, большие ViT для задач с большими данными. Выбор правильного варианта может значительно улучшить результаты.
Учитывайте вычислительные ограничения. ViT могут быть дорогими в вычислениях, особенно для изображений высокого разрешения. Рассмотрите оптимизации вроде sparse attention или использование меньших вариантов ViT, если вычислительные ресурсы ограничены.
Будущее Vision Transformers
Vision Transformers продолжают развиваться, и можно ожидать дальнейших улучшений. Рассмотрим перспективы развития.
Ожидается улучшение эффективности вычислений. Разработка более эффективных механизмов внимания, оптимизация архитектуры и использование специализированного оборудования могут сделать ViT более эффективными в вычислениях, что откроет новые возможности для применения.
Вероятно развитие мультимодальных ViT. Комбинирование ViT с языковыми моделями для создания мультимодальных систем, которые могут обрабатывать изображения и текст одновременно. Это откроет новые возможности для приложений, требующих понимания визуального и текстового контента.
Ожидается улучшение работы с ограниченными данными. Разработка новых техник обучения и архитектурных улучшений может сделать ViT более эффективными на малых датасетах, что расширит область их применения.
Вероятно появление специализированных ViT для конкретных доменов. Создание ViT, оптимизированных для конкретных областей вроде медицины, автономного вождения или робототехники, может улучшить качество и эффективность в этих областях.
Заключение
Vision Transformers представляют собой фундаментальный сдвиг в подходе к компьютерному зрению, предлагая новые возможности для моделирования глобальных зависимостей и масштабирования на больших данных. Хотя ViT имеют ограничения, особенно в требованиях к данным и вычислительной сложности, их преимущества делают их привлекательным выбором для многих задач.
Понимание принципов работы ViT, их преимуществ и ограничений важно для разработчиков, работающих с компьютерным зрением. Выбор между ViT и CNN зависит от конкретных требований задачи, и часто гибридные подходы могут быть оптимальными.
Для практического применения важно правильно выбирать варианты ViT, использовать transfer learning и оптимизировать для конкретных задач. При правильном подходе Vision Transformers могут значительно улучшить качество решений в компьютерном зрении и открыть новые возможности для приложений.
Словарь терминов
Vision Transformers (ViT) — архитектура нейронных сетей для компьютерного зрения, адаптирующая механизм внимания из языковых моделей для работы с изображениями.
Патч (Patch) — небольшой квадратный фрагмент изображения, на которое разбивается входное изображение в ViT для обработки как последовательности.
Механизм внимания (Attention Mechanism) — компонент трансформерной архитектуры, позволяющий модели фокусироваться на релевантных частях входных данных при обработке.
Самовнимание (Self-Attention) — тип механизма внимания, при котором элементы последовательности взаимодействуют друг с другом для создания обновленных представлений.
Позиционное энкодирование (Positional Encoding) — информация о позиции элементов в последовательности, добавляемая к эмбеддингам для сохранения пространственной информации.
Рецептивное поле (Receptive Field) — область входного изображения, которая влияет на активацию конкретного нейрона в сети.
Transfer Learning — техника использования предобученной модели на одной задаче для улучшения производительности на другой задаче.
Fine-tuning — процесс дообучения предобученной модели на специфических данных для адаптации к конкретной задаче.
Индуктивные предпосылки (Inductive Biases) — встроенные предположения модели о структуре данных, которые помогают обучению и обобщению.