MoE (Mixture of Experts) архитектура: как работает, почему она эффективнее
Традиционные языковые модели используют все свои параметры для обработки каждого запроса. Это означает, что для простого вопроса "Как дела?" модель задействует те же миллиарды параметров, что и для сложной задачи программирования. Такой подход неэффективен: большая часть вычислений тратится впустую. Архитектура Mixture of Experts (MoE) решает эту проблему, позволяя модели активировать только необходимые "эксперты" для каждой задачи.
MoE стала ключевой технологией в современных больших языковых моделях. GPT-4, Gemini, Claude и многие другие модели используют вариации этой архитектуры для повышения эффективности. Как работает MoE? Почему она позволяет создавать более эффективные модели? Какие преимущества и ограничения имеет этот подход? Рассмотрим принципы работы MoE, ее архитектурные особенности, практические применения и сравнение с традиционными подходами. Вы узнаете, как MoE меняет ландшафт больших языковых моделей и почему это важно для разработчиков.
Принцип работы MoE архитектуры
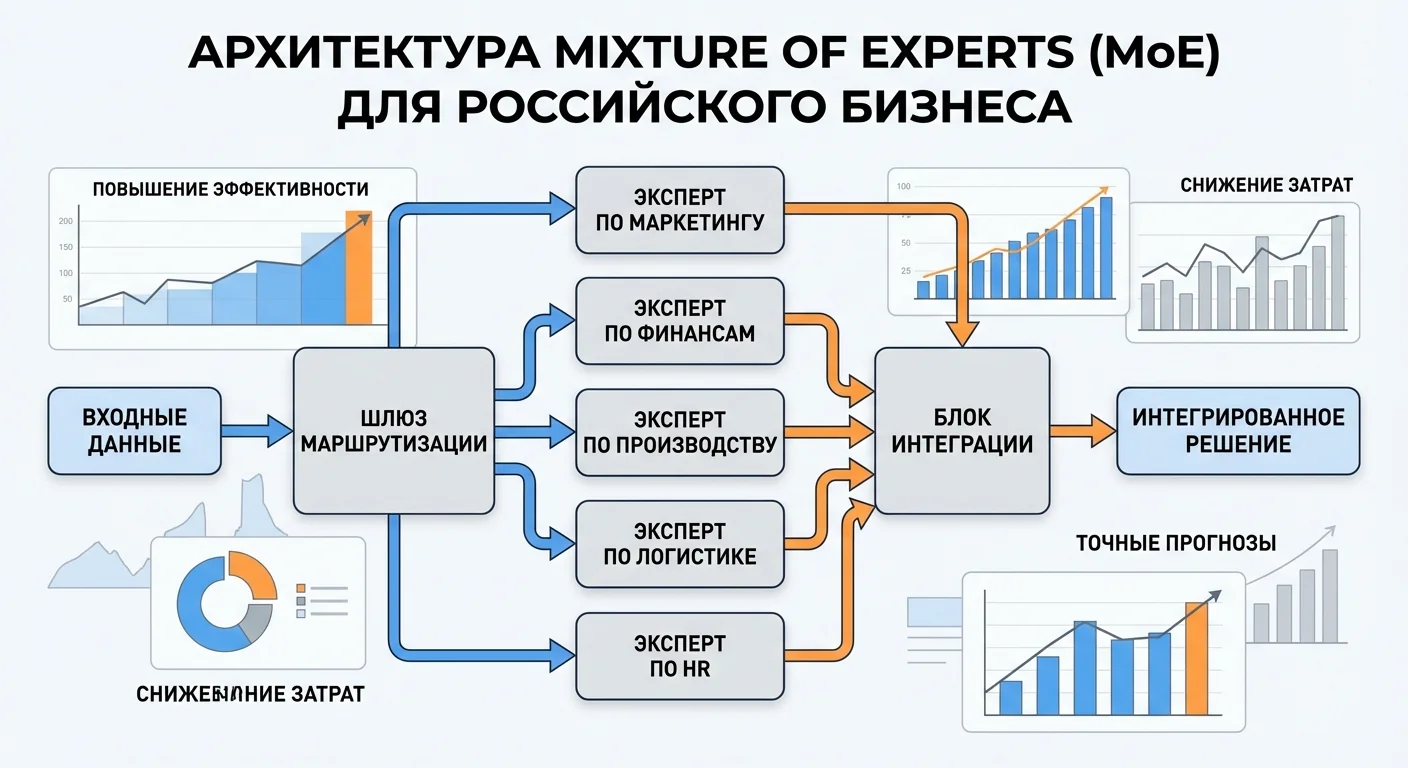
Архитектура Mixture of Experts основана на идее разделения модели на множество специализированных "экспертов" — небольших нейронных сетей, каждый из которых обучен на определенном типе задач или данных. Вместо использования всей модели для каждого запроса, система выбирает и активирует только релевантных экспертов.
Процесс работы MoE модели можно разделить на несколько этапов. Первый этап — маршрутизация (routing). Входные данные проходят через специальный слой, называемый router или gating network, который определяет, какие эксперты должны обработать запрос. Router анализирует входные данные и присваивает веса каждому эксперту, указывающие на степень их релевантности для текущей задачи.
Второй этап — активация экспертов. На основе весов от router активируются только наиболее релевантные эксперты. Обычно активируется небольшое подмножество экспертов (например, 2-4 из 8 или 16), что значительно снижает количество вычислений по сравнению с активацией всей модели. Каждый активированный эксперт обрабатывает входные данные независимо.
Третий этап — агрегация результатов. Выходы активированных экспертов объединяются с учетом их весов, полученных от router. Это может происходить через взвешенное суммирование или другие методы агрегации. Результат агрегации передается на следующий слой модели или используется как финальный выход.
Ключевое преимущество MoE — возможность создавать очень большие модели (сотни миллиардов или даже триллионы параметров), при этом активируя только небольшую часть параметров для каждого запроса. Это позволяет достичь качества больших моделей при значительно меньших вычислительных затратах.
Архитектурные компоненты MoE
MoE архитектура состоит из нескольких ключевых компонентов, каждый из которых играет важную роль в работе модели. Понимание этих компонентов помогает понять, как работает MoE и как ее можно оптимизировать.
Router или Gating Network — это компонент, который определяет, какие эксперты должны обработать входные данные. Router обычно представляет собой небольшую нейронную сеть, которая принимает входные данные и выдает распределение весов по всем экспертам. Router может быть обучен вместе с экспертами или отдельно, в зависимости от архитектуры. Качество router критически важно для эффективности MoE модели: плохой router может активировать нерелевантных экспертов, что снижает качество и эффективность.
Эксперты (Experts) — это специализированные нейронные сети, каждый из которых обучен на определенном типе задач или данных. Эксперты могут быть одинаковой архитектуры (например, все являются feed-forward сетями одинакового размера) или различаться в зависимости от задачи. В большинстве современных MoE моделей эксперты имеют одинаковую архитектуру для упрощения обучения и инференса. Каждый эксперт может специализироваться на определенных типах запросов: один на программирование, другой на математику, третий на естественный язык и так далее.
Механизм активации определяет, сколько и каких экспертов активировать для каждого запроса. Существуют различные стратегии активации: top-k (активировать k экспертов с наибольшими весами), threshold-based (активировать всех экспертов с весом выше порога), или адаптивные методы. Выбор стратегии влияет на баланс между качеством и эффективностью.
Механизм агрегации объединяет выходы активированных экспертов. Наиболее распространенный метод — взвешенное суммирование, где выходы экспертов умножаются на их веса от router и суммируются. Альтернативные методы включают конкатенацию выходов или более сложные схемы агрегации. Выбор метода агрегации может влиять на качество модели и ее способность комбинировать знания разных экспертов.
Преимущества MoE архитектуры
MoE архитектура предлагает несколько ключевых преимуществ по сравнению с традиционными плотными (dense) моделями. Понимание этих преимуществ помогает оценить, когда стоит использовать MoE.
Первое и самое важное преимущество — масштабируемость. MoE позволяет создавать модели с триллионами параметров, активируя при этом только небольшую часть для каждого запроса. Это означает, что можно достичь качества очень больших моделей при значительно меньших вычислительных затратах. Например, модель с 1 триллионом параметров может активировать только 100 миллиардов параметров для каждого запроса, что делает инференс в 10 раз быстрее и дешевле.
Второе преимущество — специализация экспертов. Каждый эксперт может специализироваться на определенном типе задач, что позволяет модели лучше справляться с разнообразными запросами. Эксперт, специализирующийся на программировании, будет лучше генерировать код, чем общая модель. Это особенно полезно для задач, требующих глубоких знаний в специфических областях.
Третье преимущество — эффективность обучения. MoE модели могут обучаться быстрее, так как разные эксперты могут обучаться параллельно на разных типах данных. Это также позволяет более эффективно использовать данные: данные программирования могут использоваться для обучения эксперта по программированию, а не тратиться на обучение всей модели.
Четвертое преимущество — гибкость и адаптивность. MoE модели могут адаптироваться к различным типам задач, активируя соответствующих экспертов. Это делает модели более универсальными и способными обрабатывать широкий спектр запросов без необходимости создания отдельных моделей для каждой задачи.
Пятое преимущество — возможность инкрементального улучшения. Новые эксперты могут быть добавлены в модель без переобучения существующих экспертов. Это позволяет постепенно улучшать модель, добавляя экспертов для новых типов задач или улучшая существующих экспертов.
Ограничения и вызовы MoE
Несмотря на преимущества, MoE архитектура имеет ряд ограничений и вызовов, которые важно учитывать при разработке и использовании таких моделей.
Первый вызов — сложность обучения. Обучение MoE модели сложнее, чем обучение плотной модели, так как необходимо обучать не только экспертов, но и router. Router должен научиться правильно распределять запросы между экспертами, что требует тщательной настройки процесса обучения. Неправильное обучение router может привести к тому, что некоторые эксперты будут использоваться редко или не будут использоваться вообще.
Второй вызов — несбалансированная нагрузка на экспертов. В процессе обучения некоторые эксперты могут стать более популярными, чем другие, что приводит к несбалансированной нагрузке. Это может снизить эффективность модели и создать узкие места в инференсе. Для решения этой проблемы используются различные техники балансировки нагрузки, такие как auxiliary loss или ограничения на распределение нагрузки.
Третий вызов — сложность инференса. Хотя MoE модели более эффективны в вычислениях, инференс может быть сложнее из-за необходимости маршрутизации и агрегации. Это может создавать накладные расходы, особенно если router не оптимизирован или если активируется слишком много экспертов. Оптимизация инференса требует тщательной настройки архитектуры и использования специализированного оборудования.
Четвертый вызов — качество агрегации. Объединение выходов нескольких экспертов может быть нетривиальной задачей. Простое взвешенное суммирование может не всегда давать оптимальные результаты, особенно если эксперты дают противоречивые ответы. Разработка эффективных методов агрегации остается активной областью исследований.
Пятый вызов — интерпретируемость. Понимание того, какие эксперты активируются для каких запросов, может быть сложным. Это затрудняет отладку модели и понимание ее поведения. Разработка инструментов для анализа и визуализации работы MoE моделей является важным направлением исследований.
Сравнение с плотными моделями
Понимание различий между MoE и плотными моделями помогает принимать обоснованные решения о выборе архитектуры. Рассмотрим ключевые различия.
Плотные модели используют все свои параметры для каждого запроса. Это означает, что вычислительная сложность инференса пропорциональна размеру модели. Для больших моделей это может быть очень дорого и медленно. Однако плотные модели проще в обучении и использовании, и их поведение более предсказуемо.
MoE модели активируют только часть параметров для каждого запроса, что делает инференс быстрее и дешевле. Однако MoE модели сложнее в обучении и могут иметь непредсказуемое поведение из-за маршрутизации. Выбор между MoE и плотной моделью зависит от конкретных требований: размера модели, типа задач, доступных ресурсов.
Для очень больших моделей (сотни миллиардов параметров и более) MoE обычно является единственным практическим выбором из-за вычислительных ограничений. Для меньших моделей выбор зависит от конкретных требований и ограничений проекта.
Практические применения MoE
MoE архитектура находит применение в различных областях, где требуется обработка разнообразных типов данных или задач. Рассмотрим основные области применения.
Большие языковые модели — основная область применения MoE. GPT-4, Gemini, Claude и многие другие современные LLM используют MoE архитектуру для масштабирования до триллионов параметров. Это позволяет создавать модели с исключительным качеством при разумных вычислительных затратах на инференс.
Мультимодальные модели также выигрывают от MoE архитектуры. Разные эксперты могут специализироваться на разных типах данных: текст, изображения, аудио. Это позволяет эффективно обрабатывать мультимодальные запросы, активируя соответствующих экспертов для каждого типа данных.
Специализированные модели для конкретных доменов могут использовать MoE для объединения экспертов из разных областей. Например, медицинская модель может иметь экспертов для разных специальностей: кардиология, онкология, неврология. Это позволяет создавать универсальные модели, которые могут обрабатывать запросы из разных областей.
Рекомендательные системы могут использовать MoE для обработки различных типов пользовательских запросов. Разные эксперты могут специализироваться на разных типах контента или пользовательских предпочтений, что позволяет создавать более точные рекомендации.
Оптимизация MoE моделей
Оптимизация MoE моделей требует внимания к нескольким аспектам: архитектуре router, балансировке нагрузки, эффективности инференса. Рассмотрим основные техники оптимизации.
Оптимизация router критически важна для эффективности MoE модели. Router должен быстро и точно определять релевантных экспертов. Это может требовать использования специализированных архитектур router или техник обучения, которые поощряют правильную маршрутизацию. Некоторые подходы используют иерархические router или адаптивные механизмы маршрутизации.
Балансировка нагрузки между экспертами важна для предотвращения узких мест. Техники балансировки включают auxiliary loss, который поощряет равномерное использование экспертов, или ограничения на распределение нагрузки. Это может требовать тщательной настройки гиперпараметров обучения.
Оптимизация инференса может включать использование специализированного оборудования, кэширования активаций экспертов, или параллельной обработки запросов. Некоторые системы используют динамическую маршрутизацию, которая адаптируется к текущей нагрузке и доступным ресурсам.
Оптимизация агрегации может улучшить качество модели. Исследования показывают, что более сложные методы агрегации могут улучшить качество, хотя и за счет увеличения вычислительной сложности. Выбор метода агрегации требует баланса между качеством и эффективностью.
Будущее MoE архитектуры
MoE архитектура продолжает развиваться, и можно ожидать дальнейших улучшений и новых применений. Рассмотрим перспективы развития.
Ожидается улучшение техник обучения MoE моделей. Исследования направлены на разработку более эффективных методов обучения router и экспертов, которые позволяют достичь лучшего качества при меньших вычислительных затратах. Это может включать использование мета-обучения или других продвинутых техник.
Вероятно развитие более сложных архитектур MoE. Иерархические MoE, где эксперты сами могут быть MoE моделями, или динамические MoE, где количество и состав экспертов адаптируются к задаче, могут открыть новые возможности.
Ожидается улучшение инструментов для работы с MoE моделями. Разработка библиотек и фреймворков, которые упрощают создание, обучение и использование MoE моделей, может сделать эту технологию более доступной для разработчиков.
Вероятно расширение применения MoE в различных областях. По мере развития технологии MoE может найти применение в областях, где сейчас используются другие подходы, открывая новые возможности для создания эффективных и масштабируемых моделей.
Заключение
MoE архитектура представляет собой мощный подход к созданию больших и эффективных языковых моделей. Разделяя модель на специализированных экспертов и активируя только релевантных для каждой задачи, MoE позволяет создавать модели с триллионами параметров при разумных вычислительных затратах на инференс.
Понимание принципов работы MoE, ее преимуществ и ограничений важно для разработчиков, работающих с большими языковыми моделями. MoE стала стандартом для современных LLM, и ее влияние на развитие AI будет только расти.
Для разработчиков важно понимать, как MoE влияет на поведение моделей и как оптимизировать работу с MoE моделями. По мере развития технологии можно ожидать появления новых инструментов и методов, которые сделают MoE еще более эффективной и доступной.
Словарь терминов
MoE (Mixture of Experts) — архитектура нейронных сетей, разделяющая модель на множество специализированных экспертов и активирующая только релевантных для каждой задачи.
Router (Gating Network) — компонент MoE модели, определяющий, какие эксперты должны обработать входные данные на основе анализа запроса.
Эксперт (Expert) — специализированная нейронная сеть в MoE модели, обученная на определенном типе задач или данных.
Маршрутизация (Routing) — процесс определения релевантных экспертов для обработки конкретного запроса.
Агрегация (Aggregation) — процесс объединения выходов активированных экспертов в финальный результат.
Плотная модель (Dense Model) — традиционная архитектура нейронной сети, использующая все параметры для каждого запроса.
Top-k активация — стратегия активации k экспертов с наибольшими весами от router.
Auxiliary Loss — дополнительная функция потерь, используемая для балансировки нагрузки между экспертами в MoE модели.
Инференс (Inference) — процесс использования обученной модели для генерации ответов на новые запросы.
Масштабируемость (Scalability) — способность системы эффективно работать при увеличении размера или сложности.